
We've updated our "Built with Cloudflare" button to make it easier to share that you're building on Cloudflare with the world. Embed it in your project's README, blog post, or wherever you want to let people know.

Check out the documentation for usage information.
Deploying static site to Workers is now easier. When you run
wrangler deploy [directory]orwrangler deploy --assets [directory]without an existing configuration file, Wrangler CLI now guides you through the deployment process with interactive prompts.Before: Required remembering multiple flags and parameters
Terminal window wrangler deploy --assets ./dist --compatibility-date 2025-09-09 --name my-projectAfter: Simple directory deployment with guided setup
Terminal window wrangler deploy dist# Interactive prompts handle the rest as shown in the example flow belowInteractive prompts for missing configuration:
- Wrangler detects when you're trying to deploy a directory of static assets
- Prompts you to confirm the deployment type
- Asks for a project name (with smart defaults)
- Automatically sets the compatibility date to today
Automatic configuration generation:
- Creates a
wrangler.jsoncfile with your deployment settings - Stores your choices for future deployments
- Eliminates the need to remember complex command-line flags
Terminal window # Deploy your built static sitewrangler deploy dist# Wrangler will prompt:✔ It looks like you are trying to deploy a directory of static assets only. Is this correct? … yes✔ What do you want to name your project? … my-astro-site# Automatically generates a wrangler.jsonc file and adds it to your project:{"name": "my-astro-site","compatibility_date": "2025-09-09","assets": {"directory": "dist"}}# Next time you run wrangler deploy, this will use the configuration in your newly generated wrangler.jsonc filewrangler deploy- You must use Wrangler version 4.24.4 or later in order to use this feature
Now, Magic WAN customers can configure a custom IKE ID for their IPsec tunnels. Customers that are using Magic WAN and a VeloCloud SD-WAN device together can utilize this new feature to create a high availability configuration.
This feature is available via API only. Customers can read the Magic WAN documentation to learn more about the Custom IKE ID feature and the API call to configure it.
Two-factor authentication is the best way to help protect your account from account takeovers, but if you lose your second factor, you could be locked out of your account. Lock outs are one of the top reasons customers contact Cloudflare support, and our policies often don't allow us to bypass two-factor authentication for customers that are locked out. Today we are releasing an improvement where Cloudflare will periodically remind you to securely save your backup codes so you don't get locked out in the future.
This week's update
This week’s focus highlights newly disclosed vulnerabilities in web frameworks, enterprise applications, and widely deployed CMS plugins. The vulnerabilities include SSRF, authentication bypass, arbitrary file upload, and remote code execution (RCE), exposing organizations to high-impact risks such as unauthorized access, system compromise, and potential data exposure. In addition, security rule enhancements have been deployed to cover general command injection and server-side injection attacks, further strengthening protections.
Key Findings
-
Next.js (CVE-2025-57822): Improper handling of redirects in custom middleware can lead to server-side request forgery (SSRF) when user-supplied headers are forwarded. Attackers could exploit this to access internal services or cloud metadata endpoints. The issue has been resolved in versions 14.2.32 and 15.4.7. Developers using custom middleware should upgrade and verify proper redirect handling in
next()calls. -
ScriptCase (CVE-2025-47227, CVE-2025-47228): In the Production Environment extension in Netmake ScriptCase through 9.12.006 (23), two vulnerabilities allow attackers to reset admin accounts and execute system commands, potentially leading to full compromise of affected deployments.
-
Sar2HTML (CVE-2025-34030): In Sar2HTML version 3.2.2 and earlier, insufficient input sanitization of the plot parameter allows remote, unauthenticated attackers to execute arbitrary system commands. Exploitation could compromise the underlying server and its data.
-
Zhiyuan OA (CVE-2025-34040): An arbitrary file upload vulnerability exists in the Zhiyuan OA platform. Improper validation in the
wpsAssistServletinterface allows unauthenticated attackers to upload crafted files via path traversal, which can be executed on the web server, leading to remote code execution. -
WordPress:Plugin:InfiniteWP Client (CVE-2020-8772): A vulnerability in the InfiniteWP Client plugin allows attackers to perform restricted actions and gain administrative control of connected WordPress sites.
Impact
These vulnerabilities could allow attackers to gain unauthorized access, execute malicious code, or take full control of affected systems. The Next.js SSRF flaw may expose internal services or cloud metadata endpoints to attackers. Exploitations of ScriptCase and Sar2HTML could result in remote code execution, administrative takeover, and full server compromise. In Zhiyuan OA, the arbitrary file upload vulnerability allows attackers to execute malicious code on the web server, potentially exposing sensitive data and applications. The authentication bypass in WordPress InfiniteWP Client enables attackers to gain administrative access, risking data exposure and unauthorized control of connected sites.
Administrators are strongly advised to apply vendor patches immediately, remove unsupported software, and review authentication and access controls to mitigate these risks.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset 100007D Command Injection - Common Attack Commands Args Log Block This rule has been merged into the original rule "Command Injection - Common Attack Commands" (ID: Cloudflare Managed Ruleset 100617 Next.js - SSRF - CVE:CVE-2025-57822 Log Block This is a New Detection Cloudflare Managed Ruleset 100659_BETA Common Payloads for Server-Side Template Injection - Beta Log Block This rule is merged into the original rule "Common Payloads for Server-Side Template Injection" (ID: Cloudflare Managed Ruleset 100824B CrushFTP - Remote Code Execution - CVE:CVE-2025-54309 - 3 Log Disabled This is a New Detection Cloudflare Managed Ruleset 100848 ScriptCase - Auth Bypass - CVE:CVE-2025-47227 Log Disabled This is a New Detection Cloudflare Managed Ruleset 100849 ScriptCase - Command Injection - CVE:CVE-2025-47228 Log Disabled This is a New Detection Cloudflare Managed Ruleset 100872 WordPress:Plugin:InfiniteWP Client - Missing Authorization - CVE:CVE-2020-8772 Log Block This is a New Detection Cloudflare Managed Ruleset 100873 Sar2HTML - Command Injection - CVE:CVE-2025-34030 Log Block This is a New Detection Cloudflare Managed Ruleset 100875 Zhiyuan OA - Remote Code Execution - CVE:CVE-2025-34040 Log Block This is a New Detection -
All bidirectional tunnel health check return packets are accepted by any Magic on-ramp.
Previously, when a Magic tunnel had a bidirectional health check configured, the bidirectional health check would pass when the return packets came back to Cloudflare over the same tunnel that was traversed by the forward packets.
There are SD-WAN devices, like VeloCloud, that do not offer controls to steer traffic over one tunnel versus another in a high availability tunnel configuration.
Now, when a Magic tunnel has a bidirectional health check configured, the bidirectional health check will pass when the return packet traverses over any tunnel in a high availability configuration.
We're excited to be a launch partner alongside Google ↗ to bring their newest embedding model, EmbeddingGemma, to Workers AI that delivers best-in-class performance for its size, enabling RAG and semantic search use cases.
@cf/google/embeddinggemma-300mis a 300M parameter embedding model from Google, built from Gemma 3 and the same research used to create Gemini models. This multilingual model supports 100+ languages, making it ideal for RAG systems, semantic search, content classification, and clustering tasks.Using EmbeddingGemma in AI Search: Now you can leverage EmbeddingGemma directly through AI Search for your RAG pipelines. EmbeddingGemma's multilingual capabilities make it perfect for global applications that need to understand and retrieve content across different languages with exceptional accuracy.
To use EmbeddingGemma for your AI Search projects:
- Go to Create in the AI Search dashboard ↗
- Follow the setup flow for your new RAG instance
- In the Generate Index step, open up More embedding models and select
@cf/google/embeddinggemma-300mas your embedding model - Complete the setup to create an AI Search
Try it out and let us know what you think!
This week's update
This week, new critical vulnerabilities were disclosed in Sitecore’s Sitecore Experience Manager (XM), Sitecore Experience Platform (XP), specifically versions 9.0 through 9.3, and 10.0 through 10.4. These flaws are caused by unsafe data deserialization and code reflection, leaving affected systems at high risk of exploitation.
Key Findings
- CVE-2025-53690: Remote Code Execution through Insecure Deserialization
- CVE-2025-53691: Remote Code Execution through Insecure Deserialization
- CVE-2025-53693: HTML Cache Poisoning through Unsafe Reflections
Impact
Exploitation could allow attackers to execute arbitrary code remotely on the affected system and conduct cache poisoning attacks, potentially leading to further compromise. Applying the latest vendor-released solution without delay is strongly recommended.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset 100878 Sitecore - Remote Code Execution - CVE:CVE-2025-53691 N/A Block This is a new detection Cloudflare Managed Ruleset 100631 Sitecore - Cache Poisoning - CVE:CVE-2025-53693 N/A Block This is a new detection Cloudflare Managed Ruleset 100879 Sitecore - Remote Code Execution - CVE:CVE-2025-53690 N/A Block This is a new detection
You can now upload up to 100,000 static assets per Worker version
- Paid and Workers for Platforms users can now upload up to 100,000 static assets per Worker version, a 5x increase from the previous limit of 20,000.
- Customers on the free plan still have the same limit as before — 20,000 static assets per version of your Worker
- The individual file size limit of 25 MiB remains unchanged for all customers.
This increase allows you to build larger applications with more static assets without hitting limits.
To take advantage of the increased limits, you must use Wrangler version 4.34.0 or higher. Earlier versions of Wrangler will continue to enforce the previous 20,000 file limit.
For more information about Workers static assets, see the Static Assets documentation and Platform Limits.
You can now manage Workers, Versions, and Deployments as separate resources with a new, resource-oriented API (Beta).
This new API is supported in the Cloudflare Terraform provider ↗ and the Cloudflare Typescript SDK ↗, allowing platform teams to manage a Worker's infrastructure in Terraform, while development teams handle code deployments from a separate repository or workflow. We also designed this API with AI agents in mind, as a clear, predictable structure is essential for them to reliably build, test, and deploy applications.
- New beta API endpoints
- Cloudflare TypeScript SDK v5.0.0 ↗
- Cloudflare Go SDK v6.0.0 ↗
- Terraform provider v5.9.0 ↗:
cloudflare_worker↗ ,cloudflare_worker_version↗, andcloudflare_workers_deployments↗ resources. - See full examples in our Infrastructure as Code (IaC) guide
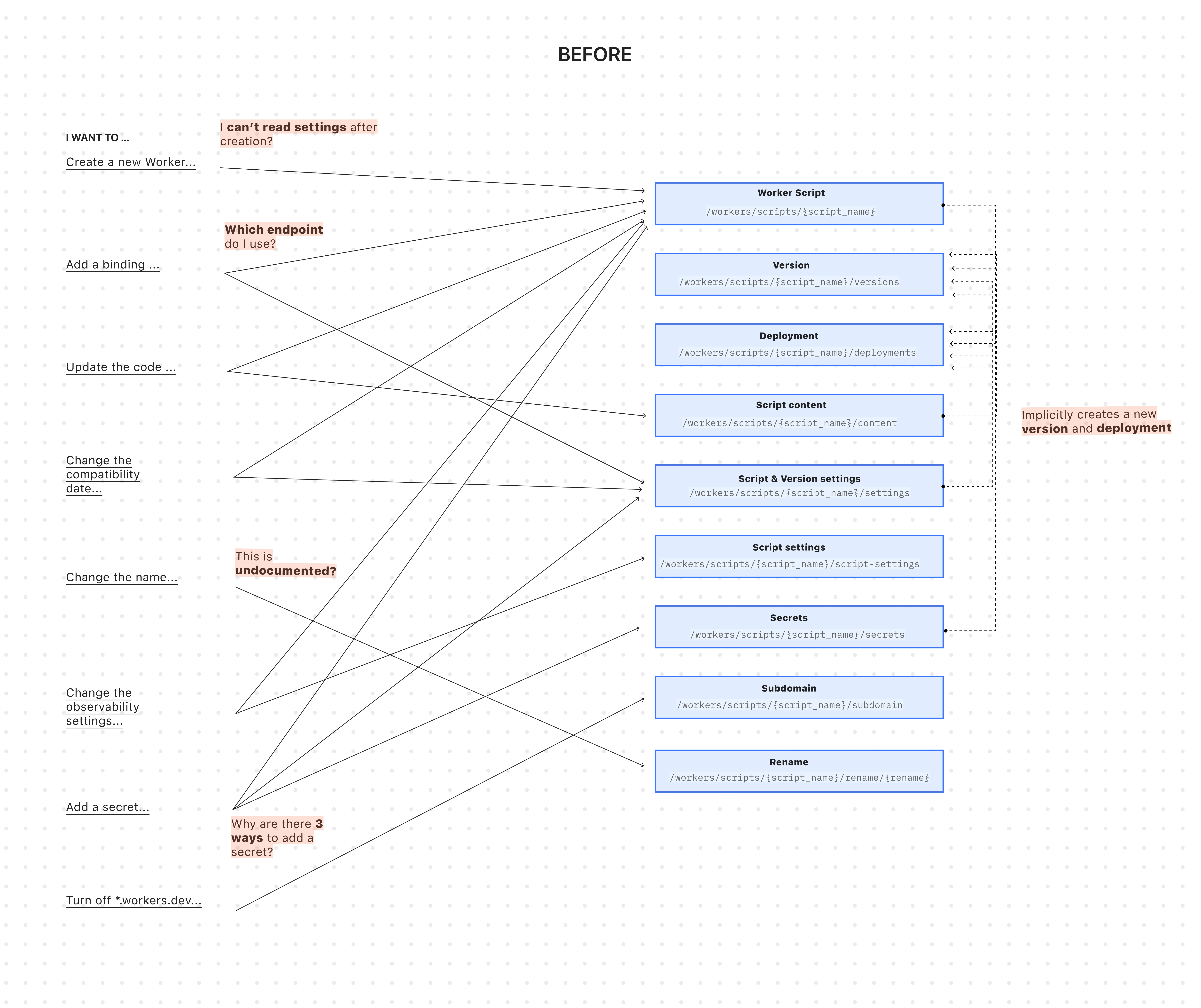
The existing API was originally designed for simple, one-shot script uploads:
Terminal window curl -X PUT "https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/workers/scripts/$SCRIPT_NAME" \-H "X-Auth-Email: $CLOUDFLARE_EMAIL" \-H "X-Auth-Key: $CLOUDFLARE_API_KEY" \-H "Content-Type: multipart/form-data" \-F 'metadata={"main_module": "worker.js","compatibility_date": "$today$"}' \-F "worker.js=@worker.js;type=application/javascript+module"This API worked for creating a basic Worker, uploading all of its code, and deploying it immediately — but came with challenges:
-
A Worker couldn't exist without code: To create a Worker, you had to upload its code in the same API request. This meant platform teams couldn't provision Workers with the proper settings, and then hand them off to development teams to deploy the actual code.
-
Several endpoints implicitly created deployments: Simple updates like adding a secret or changing a script's content would implicitly create a new version and immediately deploy it.
-
Updating a setting was confusing: Configuration was scattered across eight endpoints with overlapping responsibilities. This ambiguity made it difficult for human developers (and even more so for AI agents) to reliably update a Worker via API.
-
Scripts used names as primary identifiers: This meant simple renames could turn into a risky migration, requiring you to create a brand new Worker and update every reference. If you were using Terraform, this could inadvertently destroy your Worker altogether.
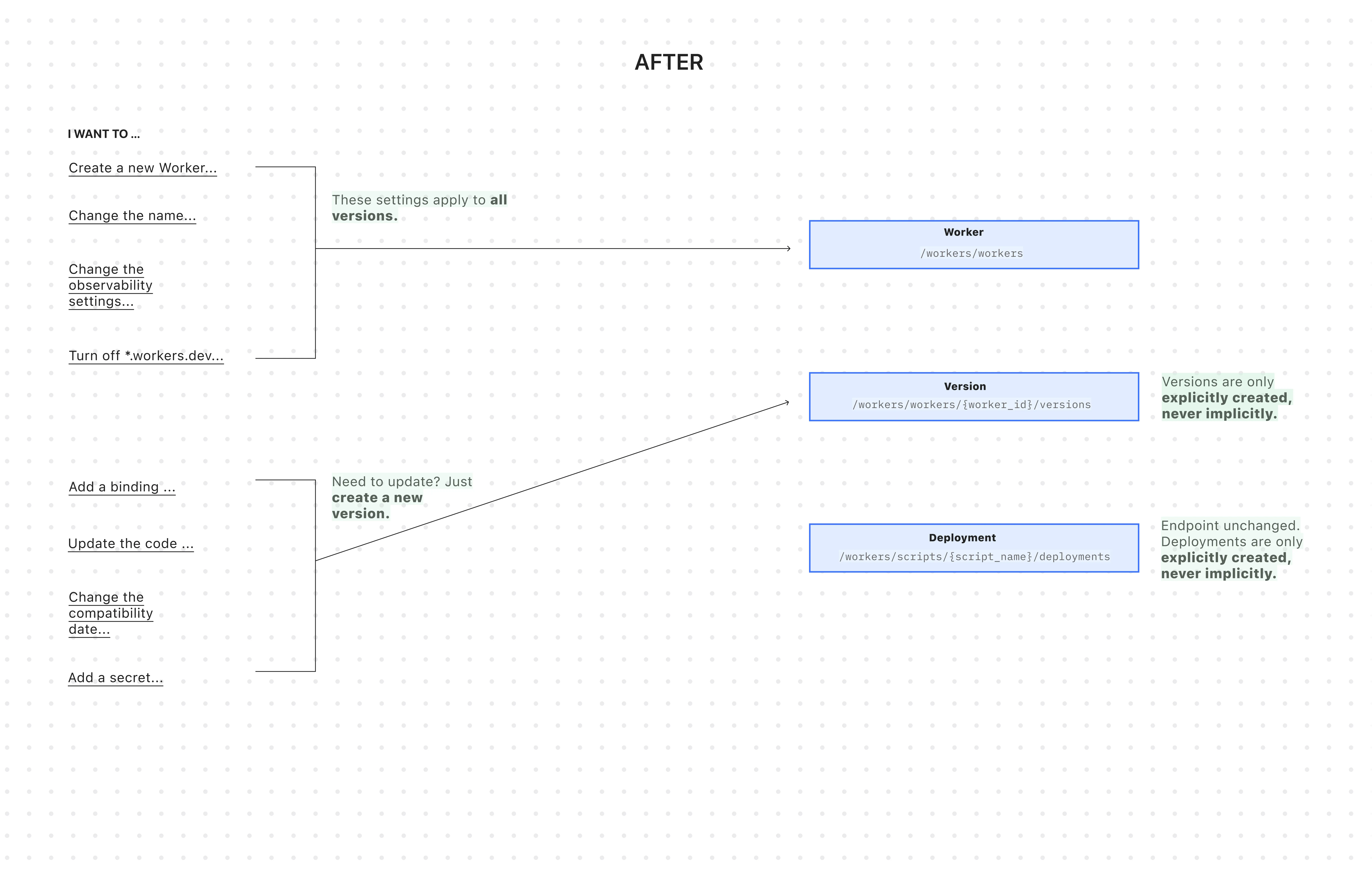
All endpoints now use simple JSON payloads, with script content embedded as
base64-encoded strings -- a more consistent and reliable approach than the previousmultipart/form-dataformat.-
Worker: The parent resource representing your application. It has a stable UUID and holds persistent settings like
name,tags, andlogpush. You can now create a Worker to establish its identity and settings before any code is uploaded. -
Version: An immutable snapshot of your code and its specific configuration, like bindings and
compatibility_date. Creating a new version is a safe action that doesn't affect live traffic. -
Deployment: An explicit action that directs traffic to a specific version.
Workers are now standalone resources that can be created and configured without any code. Platform teams can provision Workers with the right settings, then hand them off to development teams for implementation.
TypeScript // Step 1: Platform team creates the Worker resource (no code needed)const worker = await client.workers.beta.workers.create({name: "payment-service",account_id: "...",observability: {enabled: true,},});// Step 2: Development team adds code and creates a version laterconst version = await client.workers.beta.workers.versions.create(worker.id, {account_id: "...",main_module: "worker.js",compatibility_date: "$today",bindings: [ /*...*/ ],modules: [{name: "worker.js",content_type: "application/javascript+module",content_base64: Buffer.from(scriptContent).toString("base64"),},],});// Step 3: Deploy explicitly when readyconst deployment = await client.workers.scripts.deployments.create(worker.name, {account_id: "...",strategy: "percentage",versions: [{percentage: 100,version_id: version.id,},],});If you use Terraform, you can now declare the Worker in your Terraform configuration and manage configuration outside of Terraform in your Worker's
wrangler.jsoncfile and deploy code changes using Wrangler.resource "cloudflare_worker" "my_worker" {account_id = "..."name = "my-important-service"}# Manage Versions and Deployments here or outside of Terraform# resource "cloudflare_worker_version" "my_worker_version" {}# resource "cloudflare_workers_deployment" "my_worker_deployment" {}Creating a version and deploying it are now always explicit, separate actions - never implicit side effects. To update version-specific settings (like bindings), you create a new version with those changes. The existing deployed version remains unchanged until you explicitly deploy the new one.
Terminal window # Step 1: Create a new version with updated settings (doesn't affect live traffic)POST /workers/workers/{id}/versions{"compatibility_date": "$today","bindings": [{"name": "MY_NEW_ENV_VAR","text": "new_value","type": "plain_text"}],"modules": [...]}# Step 2: Explicitly deploy when ready (now affects live traffic)POST /workers/scripts/{script_name}/deployments{"strategy": "percentage","versions": [{"percentage": 100,"version_id": "new_version_id"}]}Configuration is now logically divided: Worker settings (like
nameandtags) persist across all versions, while Version settings (likebindingsandcompatibility_date) are specific to each code snapshot.Terminal window # Worker settings (the parent resource)PUT /workers/workers/{id}{"name": "payment-service","tags": ["production"],"logpush": true,}Terminal window # Version settings (the "code")POST /workers/workers/{id}/versions{"compatibility_date": "$today","bindings": [...],"modules": [...]}The
/workers/workers/path now supports addressing a Worker by both its immutable UUID and its mutable name.Terminal window # Both work for the same WorkerGET /workers/workers/29494978e03748669e8effb243cf2515 # UUID (stable for automation)GET /workers/workers/payment-service # Name (convenient for humans)This dual approach means:
- Developers can use readable names for debugging.
- Automation can rely on stable UUIDs to prevent errors when Workers are renamed.
- Terraform can rename Workers without destroying and recreating them.
- The pre-existing Workers REST API remains fully supported. Once the new API exits beta, we'll provide a migration timeline with ample notice and comprehensive migration guides.
- Existing Terraform resources and SDK methods will continue to be fully supported through the current major version.
- While the Deployments API currently remains on the
/scripts/endpoint, we plan to introduce a new Deployments endpoint under/workers/to match the new API structure.
Cloudflare's API now supports rate limiting headers using the pattern developed by the IETF draft on rate limiting ↗. This allows API consumers to know how many more calls are left until the rate limit is reached, as well as how long you will need to wait until more capacity is available.
Our SDKs automatically work with these new headers, backing off when rate limits are approached. There is no action required for users of the latest Cloudflare SDKs to take advantage of this.
As always, if you need any help with rate limits, please contact Support.
Headers that are always returned:
Ratelimit: List of service limit items, composed of the limit name, the remaining quota (r) and the time next window resets (t). For example:"default";r=50;t=30Ratelimit-Policy: List of quota policy items, composed of the policy name, the total quota (q) and the time window the quota applies to (w). For example:"burst";q=100;w=60
Returned only when a rate limit has been reached (error code: 429):
- Retry-After: Number of Seconds until more capacity is available, rounded up
- All of Cloudflare's latest SDKs will automatically respond to the headers, instituting a backoff when limits are approached.
These new headers and back offs are only available for Cloudflare REST APIs, and will not affect GraphQL.
Log Explorer now supports logging and filtering on header or cookie fields in the
http_requestsdataset.Create a custom field to log desired header or cookie values into the
http_requestsdataset and Log Explorer will import these as searchable fields. Once configured, use the custom SQL editor in Log Explorer to view or filter on these requests.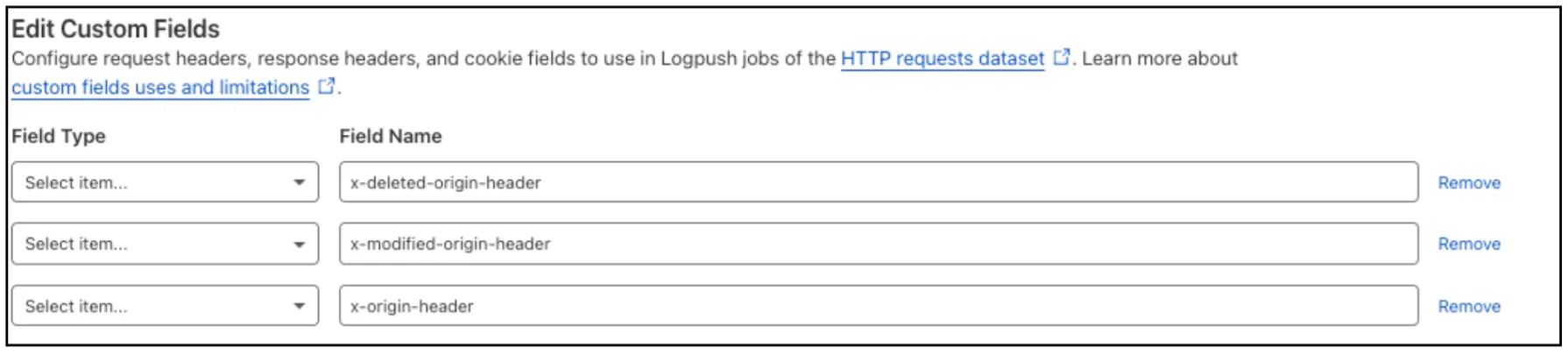
For more details, refer to Headers and cookies.
Starting December 1, 2025, list endpoints for the Cloudflare Tunnel API and Zero Trust Networks API will no longer return deleted tunnels, routes, subnets and virtual networks by default. This change makes the API behavior more intuitive by only returning active resources unless otherwise specified.
No action is required if you already explicitly set
is_deleted=falseor if you only need to list active resources.This change affects the following API endpoints:
- List all tunnels:
GET /accounts/{account_id}/tunnels - List Cloudflare Tunnels:
GET /accounts/{account_id}/cfd_tunnel - List WARP Connector tunnels:
GET /accounts/{account_id}/warp_connector - List tunnel routes:
GET /accounts/{account_id}/teamnet/routes - List subnets:
GET /accounts/{account_id}/zerotrust/subnets - List virtual networks:
GET /accounts/{account_id}/teamnet/virtual_networks
The default behavior of the
is_deletedquery parameter will be updated.Scenario Previous behavior (before December 1, 2025) New behavior (from December 1, 2025) is_deletedparameter is omittedReturns active & deleted tunnels, routes, subnets and virtual networks Returns only active tunnels, routes, subnets and virtual networks If you need to retrieve deleted (or all) resources, please update your API calls to explicitly include the
is_deletedparameter before December 1, 2025.To get a list of only deleted resources, you must now explicitly add the
is_deleted=truequery parameter to your request:Terminal window # Example: Get ONLY deleted Tunnelscurl "https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/tunnels?is_deleted=true" \-H "Authorization: Bearer $API_TOKEN"# Example: Get ONLY deleted Virtual Networkscurl "https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/teamnet/virtual_networks?is_deleted=true" \-H "Authorization: Bearer $API_TOKEN"Following this change, retrieving a complete list of both active and deleted resources will require two separate API calls: one to get active items (by omitting the parameter or using
is_deleted=false) and one to get deleted items (is_deleted=true).This update is based on user feedback and aims to:
- Create a more intuitive default: Aligning with common API design principles where list operations return only active resources by default.
- Reduce unexpected results: Prevents users from accidentally operating on deleted resources that were returned unexpectedly.
- Improve performance: For most users, the default query result will now be smaller and more relevant.
To learn more, please visit the Cloudflare Tunnel API and Zero Trust Networks API documentation.
- List all tunnels:
To provide more granular controls, we refined the existing roles for Email security and launched a new Email security role as well.
All Email security roles no longer have read or write access to any of the other Zero Trust products:
- Email Configuration Admin
- Email Integration Admin
- Email security Read Only
- Email security Analyst
- Email security Policy Admin
- Email security Reporting
To configure Data Loss Prevention (DLP) or Remote Browser Isolation (RBI), you now need to be an admin for the Zero Trust dashboard with the Cloudflare Zero Trust role.
Also through customer feedback, we have created a new additive role to allow Email security Analyst to create, edit, and delete Email security policies, without needing to provide access via the Email Configuration Admin role. This role is called Email security Policy Admin, which can read all settings, but has write access to allow policies, trusted domains, and blocked senders.
This feature is available across these Email security packages:
- Advantage
- Enterprise
- Enterprise + PhishGuard
This week's update
This week, a critical vulnerability was disclosed in Fortinet FortiWeb (versions 7.6.3 and below, versions 7.4.7 and below, versions 7.2.10 and below, and versions 7.0.10 and below), linked to improper parameter handling that could allow unauthorized access.
Key Findings
- Fortinet FortiWeb (CVE-2025-52970): A vulnerability may allow an unauthenticated remote attacker with access to non-public information to log in as any existing user on the device via a specially crafted request.
Impact
Exploitation could allow an unauthenticated attacker to impersonate any existing user on the device, potentially enabling them to modify system settings or exfiltrate sensitive information, posing a serious security risk. Upgrading to the latest vendor-released version is strongly recommended.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset 100586 Fortinet FortiWeb - Auth Bypass - CVE:CVE-2025-52970 Log Disabled This is a New Detection Cloudflare Managed Ruleset 100136C XSS - JavaScript - Headers and Body N/A N/A Rule metadata description refined. Detection unchanged.
Smart Tiered Cache now falls back to Generic Tiered Cache when the origin location cannot be determined, improving cache precision for your content.
Previously, when Smart Tiered Cache was unable to select the optimal upper tier (such as when origins are masked by Anycast IPs), latency could be negatively impacted. This fallback now uses Generic Tiered Cache instead, providing better performance and cache efficiency.
When Smart Tiered Cache falls back to Generic Tiered Cache:
- Multiple upper-tiers: Uses all of Cloudflare's global data centers as a network of upper-tiers instead of a single optimal location.
- Distributed cache requests: Lower-tier data centers can query any available upper-tier for cached content.
- Improved global coverage: Provides better cache hit ratios across geographically distributed visitors.
- Automatic fallback: Seamlessly transitions when origin location cannot be determined, such as with Anycast-masked origins.
- Preserves high performance during fallback: Smart Tiered Cache now maintains strong cache efficiency even when optimal upper tier selection is not possible.
- Minimizes latency impact: Automatically uses Generic Tiered Cache topology to keep performance high when origin location cannot be determined.
- Seamless experience: No configuration changes or intervention required when fallback occurs.
- Improved resilience: Smart Tiered Cache remains effective across diverse origin infrastructure, including Anycast-masked origins.
This improvement is automatically applied to all zones using Smart Tiered Cache. No action is required on your part.
We're excited to share a new AI feature, the WARP diagnostic analyzer ↗, to help you troubleshoot and resolve WARP connectivity issues faster. This beta feature is now available in the Zero Trust dashboard ↗ to all users. The AI analyzer makes it easier for you to identify the root cause of client connectivity issues by parsing remote captures of WARP diagnostic logs. The WARP diagnostic analyzer provides a summary of impact that may be experienced on the device, lists notable events that may contribute to performance issues, and recommended troubleshooting steps and articles to help you resolve these issues. Refer to WARP diagnostics analyzer (beta) to learn more about how to maximize using the WARP diagnostic analyzer to troubleshoot the WARP client.
Digital Experience Monitoring (DEX) provides visibility into device connectivity and performance across your Cloudflare SASE deployment.
We've released an MCP server (Model Context Protocol) ↗ for DEX.
The DEX MCP server is an AI tool that allows customers to ask a question like, "Show me the connectivity and performance metrics for the device used by carly@acme.com", and receive an answer that contains data from the DEX API.
Any Cloudflare One customer using a Free, PayGo, or Enterprise account can access the DEX MCP Server. This feature is available to everyone.
Customers can test the new DEX MCP server in less than one minute. To learn more, read the DEX MCP server documentation.
Earlier this year, we announced the launch of the new Terraform v5 Provider. We are aware of the high number of issues ↗ reported by the Cloudflare community related to the v5 release. We have committed to releasing improvements on a 2 week cadence to ensure its stability and reliability, including the v5.9 release. We have also pivoted from an issue-to-issue approach to a resource-per-resource approach - we will be focusing on specific resources for every release, stabilizing the release, and closing all associated bugs with that resource before moving onto resolving migration issues.
Thank you for continuing to raise issues. We triage them weekly and they help make our products stronger.
This release includes a new resource,
cloudflare_snippet, which replacescloudflare_snippets.cloudflare_snippetis now considered deprecated but can still be used. Please utilizecloudflare_snippetas soon as possible.- Resources stabilized:
cloudflare_zone_settingcloudflare_worker_scriptcloudflare_worker_routetiered_cache
- NEW resource
cloudflare_snippetwhich should be used in place ofcloudflare_snippets.cloudflare_snippetsis now deprecated. This enables the management of Cloudflare's snippet functionality through Terraform. - DNS Record Improvements: Enhanced handling of DNS record drift detection
- Load Balancer Fixes: Resolved
created_onfield inconsistencies and improved pool configuration handling - Bot Management: Enhanced auto-update model state consistency and fight mode configurations
- Other bug fixes
For a more detailed look at all of the changes, refer to the changelog ↗ in GitHub.
- #5921: In cloudflare_ruleset removing an existing rule causes recreation of later rules ↗
- #5904: cloudflare_zero_trust_access_application is not idempotent ↗
- #5898: (cloudflare_workers_script) Durable Object migrations not applied ↗
- #5892: cloudflare_workers_script secret_text environment variable gets replaced on every deploy ↗
- #5891: cloudflare_zone suddenly started showing drift ↗
- #5882: cloudflare_zero_trust_list always marked for change due to read only attributes ↗
- #5879: cloudflare_zero_trust_gateway_certificate unable to manage resource (cant mark as active/inactive) ↗
- #5858: cloudflare_dns_records is always updated in-place ↗
- #5839: Recurring change on cloudflare_zero_trust_gateway_policy after upgrade to V5 provider & also setting expiration fails ↗
- #5811: Reusable policies are imported as inline type for cloudflare_zero_trust_access_application ↗
- #5795: cloudflare_zone_setting inconsistent value of "editable" upon apply ↗
- #5789: Pagination issue fetching all policies in "cloudflare_zero_trust_access_policies" data source ↗
- #5770: cloudflare_zero_trust_access_application type warp diff on every apply ↗
- #5765: V5 / cloudflare_zone_dnssec fails with HTTP/400 "Malformed request body" ↗
- #5755: Unable to manage Cloudflare managed WAF rules via Terraform ↗
- #5738: v4 to v5 upgrade failing Error: no schema available AND Unable to Read Previously Saved State for UpgradeResourceState ↗
- #5727: cloudflare_ruleset http_request_cache_settings bypass mismatch between dashboard and terraform ↗
- #5700: cloudflare_account_member invalid type 'string' for field 'roles' ↗
If you have an unaddressed issue with the provider, we encourage you to check the open issues ↗ and open a new issue if one does not already exist for what you are experiencing.
We suggest holding off on migration to v5 while we work on stabilization. This help will you avoid any blocking issues while the Terraform resources are actively being stabilized.
If you'd like more information on migrating from v4 to v5, please make use of the migration guide ↗. We have provided automated migration scripts using Grit which simplify the transition. These do not support implementations which use Terraform modules, so customers making use of modules need to migrate manually. Please make use of
terraform planto test your changes before applying, and let us know if you encounter any additional issues by reporting to our GitHub repository ↗.- Resources stabilized:
This week's update
This week, new critical vulnerabilities were disclosed in Next.js’s image optimization functionality, exposing a broad range of production environments to risks of data exposure and cache manipulation.
Key Findings
-
CVE-2025-55173: Arbitrary file download from the server via image optimization.
-
CVE-2025-57752: Cache poisoning leading to unauthorized data disclosure.
Impact
Exploitation could expose sensitive files, leak user or backend data, and undermine application trust. Given Next.js’s wide use, immediate patching and cache hardening are strongly advised.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset 100613 Next.js - Dangerous File Download - CVE:CVE-2025-55173 N/A Block This is a new detection Cloudflare Managed Ruleset 100616 Next.js - Information Disclosure - CVE:CVE-2025-57752 N/A Block This is a new detection -
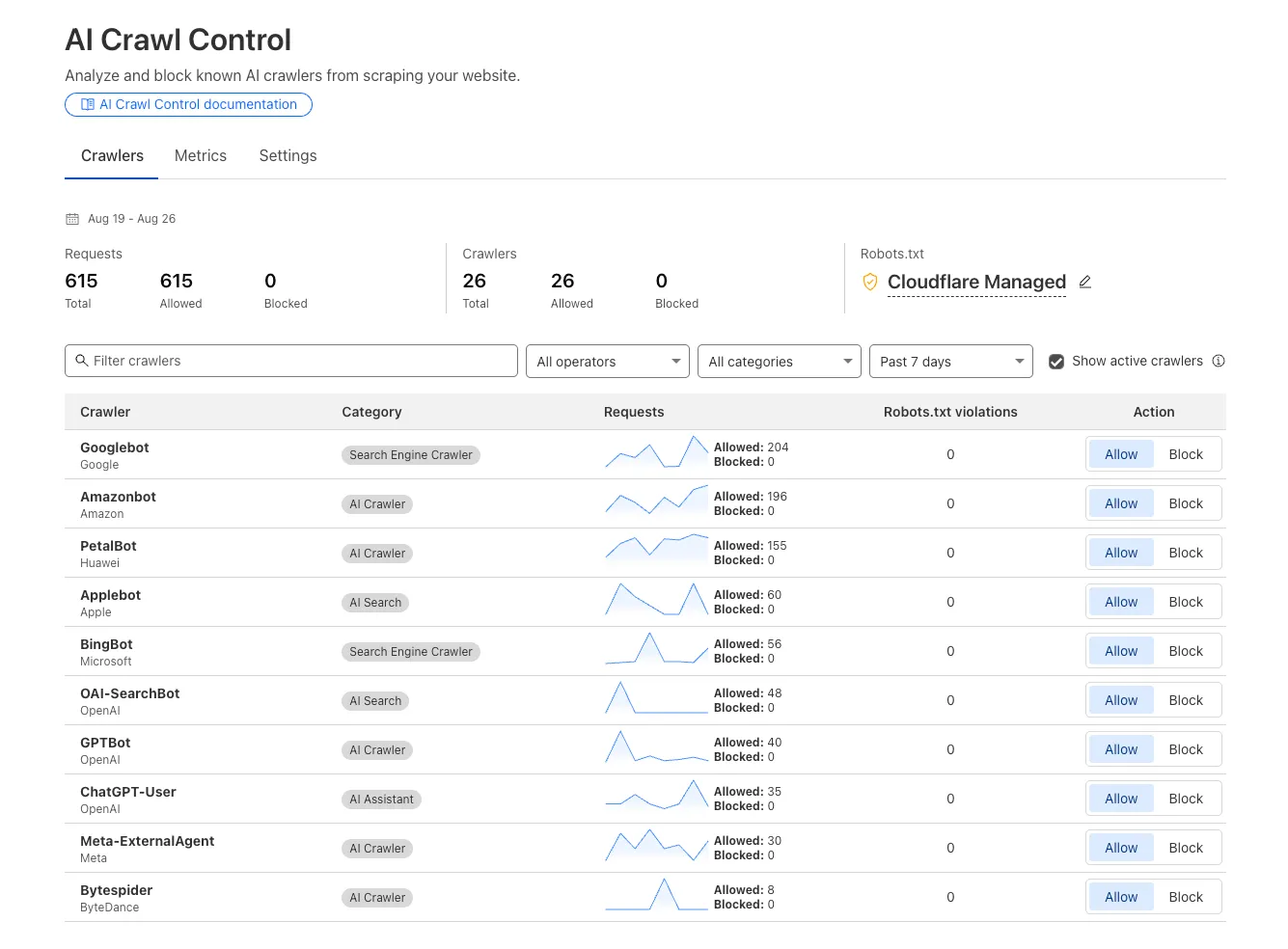
We improved AI crawler management with detailed analytics and introduced custom HTTP 402 responses for blocked crawlers. AI Audit has been renamed to AI Crawl Control and is now generally available.
Enhanced Crawlers tab:
- View total allowed and blocked requests for each AI crawler
- Trend charts show crawler activity over your selected time range per crawler
Custom block responses (paid plans): You can now return HTTP 402 "Payment Required" responses when blocking AI crawlers, enabling direct communication with crawler operators about licensing terms.
For users on paid plans, when blocking AI crawlers you can configure:
- Response code: Choose between 403 Forbidden or 402 Payment Required
- Response body: Add a custom message with your licensing contact information
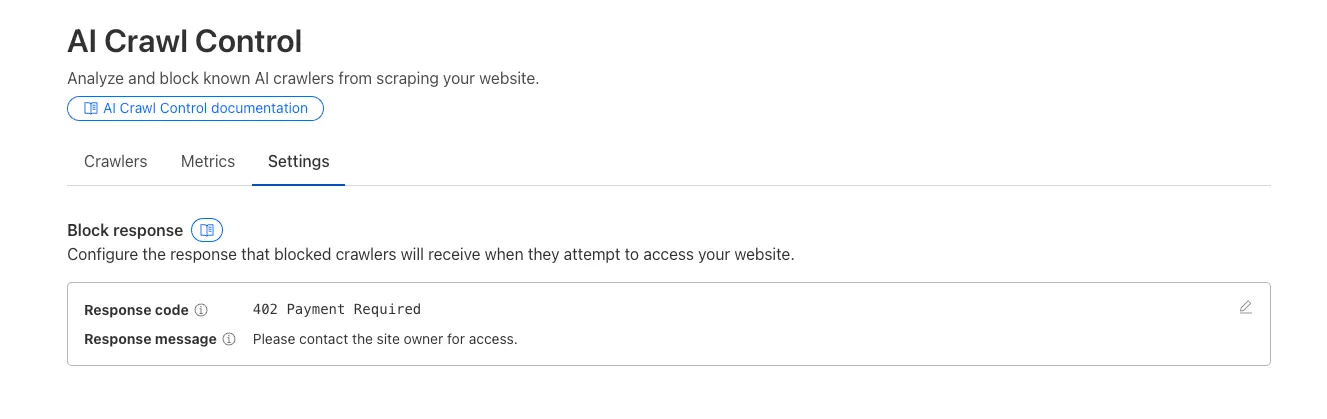
Example 402 response:
HTTP 402 Payment RequiredDate: Mon, 24 Aug 2025 12:56:49 GMTContent-type: application/jsonServer: cloudflareCf-Ray: 967e8da599d0c3fa-EWRCf-Team: 2902f6db750000c3fa1e2ef400000001{"message": "Please contact the site owner for access."}
Zero Trust has significantly upgraded its Shadow IT analytics, providing you with unprecedented visibility into your organizations use of SaaS tools. With this dashboard, you can review who is using an application and volumes of data transfer to the application.
You can review these metrics against application type, such as Artificial Intelligence or Social Media. You can also mark applications with an approval status, including Unreviewed, In Review, Approved, and Unapproved designating how they can be used in your organization.
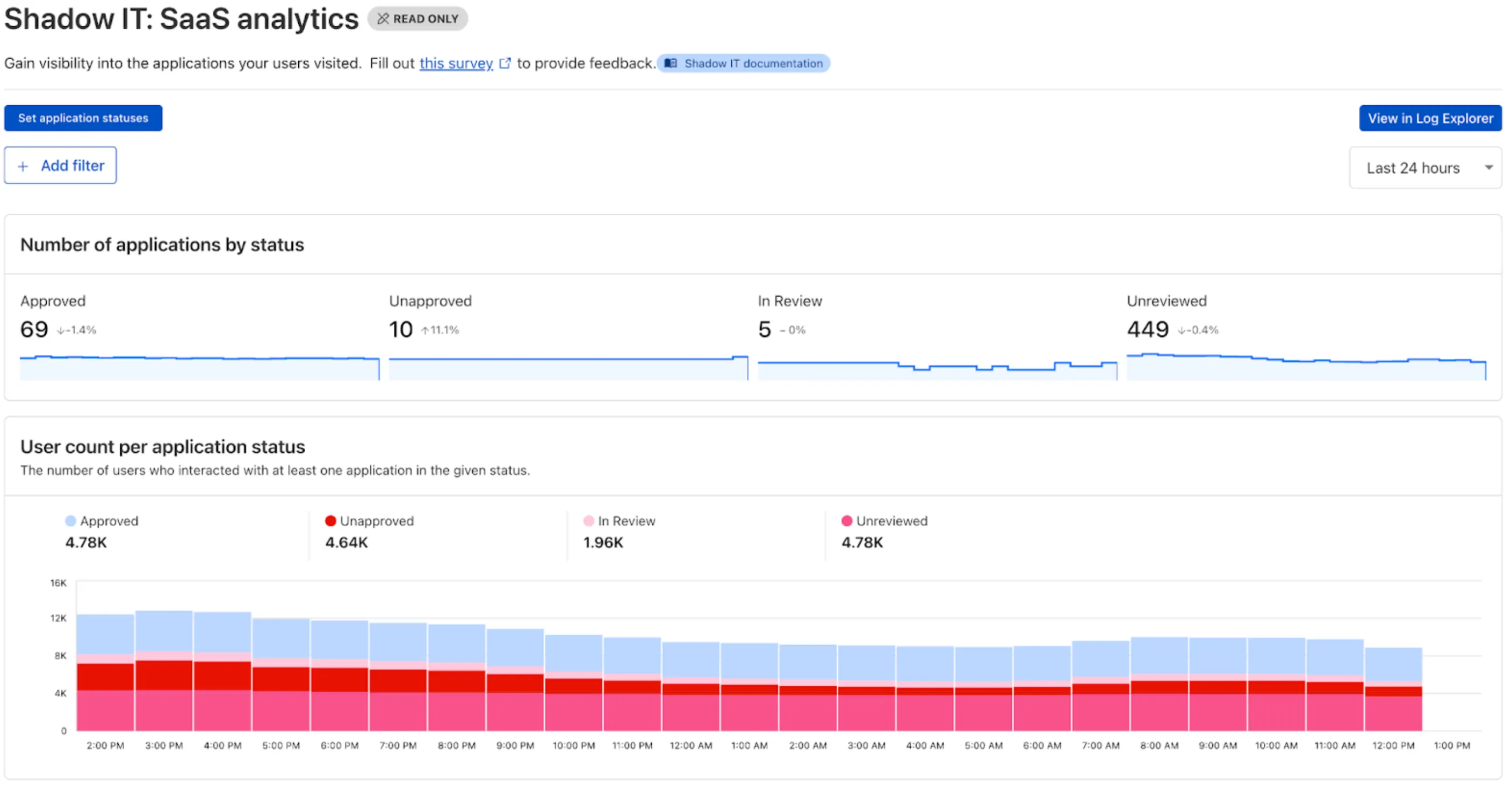
These application statuses can also be used in Gateway HTTP policies, so you can block, isolate, limit uploads and downloads, and more based on the application status.
Both the analytics and policies are accessible in the Cloudflare Zero Trust dashboard ↗, empowering organizations with better visibility and control.
New state-of-the-art models have landed on Workers AI! This time, we're introducing new partner models trained by our friends at Deepgram ↗ and Leonardo ↗, hosted on Workers AI infrastructure.
As well, we're introuding a new turn detection model that enables you to detect when someone is done speaking — useful for building voice agents!
Read the blog ↗ for more details and check out some of the new models on our platform:
@cf/deepgram/aura-1is a text-to-speech model that allows you to input text and have it come to life in a customizable voice@cf/deepgram/nova-3is speech-to-text model that transcribes multilingual audio at a blazingly fast speed@cf/pipecat-ai/smart-turn-v2helps you detect when someone is done speaking@cf/leonardo/lucid-originis a text-to-image model that generates images with sharp graphic design, stunning full-HD renders, or highly specific creative direction@cf/leonardo/phoenix-1.0is a text-to-image model with exceptional prompt adherence and coherent text
You can filter out new partner models with the
Partnercapability on our Models page.As well, we're introducing WebSocket support for some of our audio models, which you can filter though the
Realtimecapability on our Models page. WebSockets allows you to create a bi-directional connection to our inference server with low latency — perfect for those that are building voice agents.An example python snippet on how to use WebSockets with our new Aura model:
import jsonimport osimport asyncioimport websocketsuri = f"wss://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/run/@cf/deepgram/aura-1"input = ["Line one, out of three lines that will be provided to the aura model.","Line two, out of three lines that will be provided to the aura model.","Line three, out of three lines that will be provided to the aura model. This is a last line.",]async def text_to_speech():async with websockets.connect(uri, additional_headers={"Authorization": os.getenv("CF_TOKEN")}) as websocket:print("connection established")for line in input:print(f"sending `{line}`")await websocket.send(json.dumps({"type": "Speak", "text": line}))print("line was sent, flushing")await websocket.send(json.dumps({"type": "Flush"}))print("flushed, recving")resp = await websocket.recv()print(f"response received {resp}")if __name__ == "__main__":asyncio.run(text_to_speech())
Cloudflare CASB ↗ now supports three of the most widely used GenAI platforms — OpenAI ChatGPT, Anthropic Claude, and Google Gemini. These API-based integrations give security teams agentless visibility into posture, data, and compliance risks across their organization’s use of generative AI.
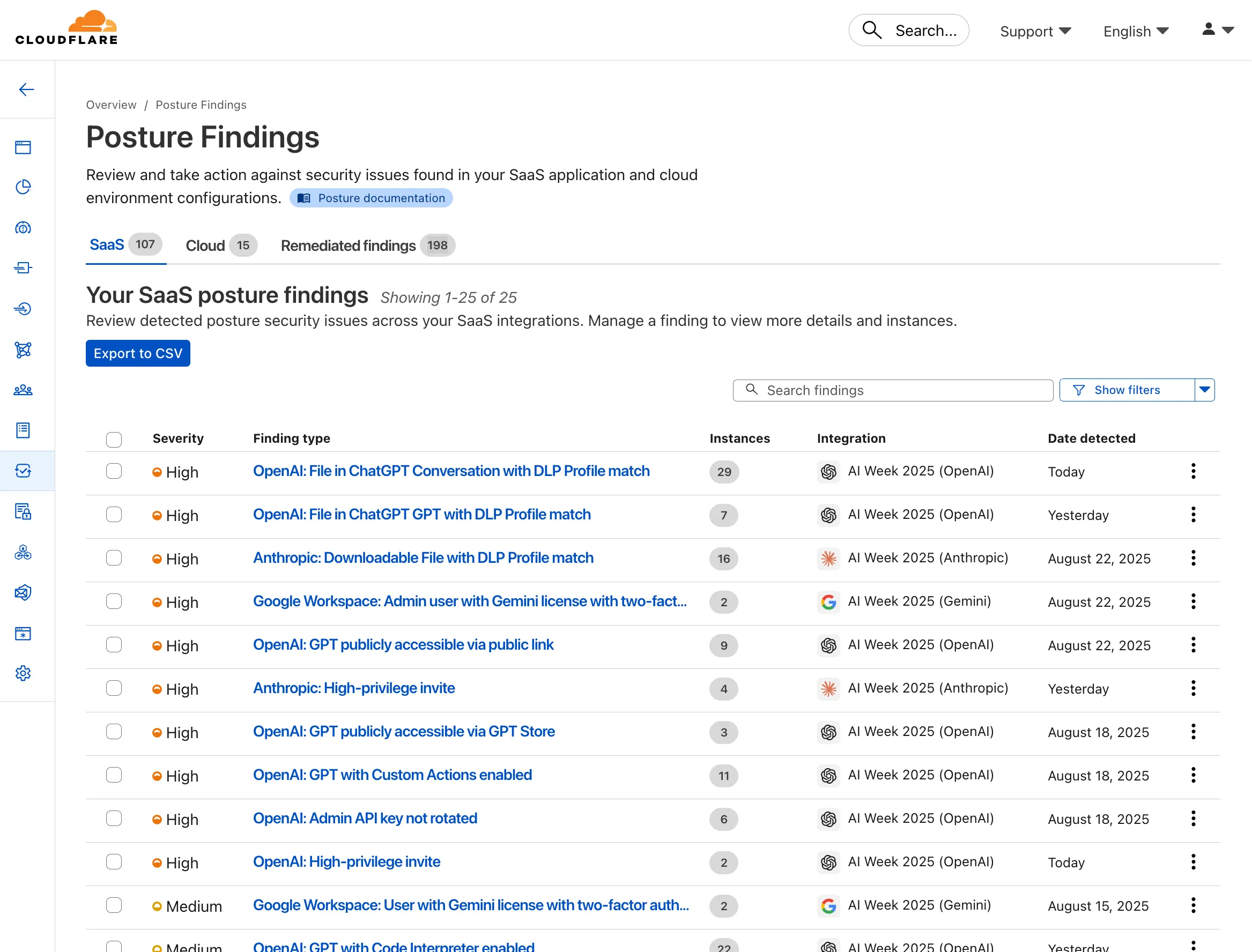
- Agentless connections — connect ChatGPT, Claude, and Gemini tenants via API; no endpoint software required
- Posture management — detect insecure settings and misconfigurations that could lead to data exposure
- DLP detection — identify sensitive data in uploaded chat attachments or files
- GenAI-specific insights — surface risks unique to each provider’s capabilities
These integrations are available to all Cloudflare One customers today.
You can now control who within your organization has access to internal MCP servers, by putting internal MCP servers behind Cloudflare Access.
Self-hosted applications in Cloudflare Access now support OAuth for MCP server authentication. This allows Cloudflare to delegate access from any self-hosted application to an MCP server via OAuth. The OAuth access token authorizes the MCP server to make requests to your self-hosted applications on behalf of the authorized user, using that user's specific permissions and scopes.
For example, if you have an MCP server designed for internal use within your organization, you can configure Access policies to ensure that only authorized users can access it, regardless of which MCP client they use. Support for internal, self-hosted MCP servers also works with MCP server portals, allowing you to provide a single MCP endpoint for multiple MCP servers. For more on MCP server portals, read the blog post ↗ on the Cloudflare Blog.