
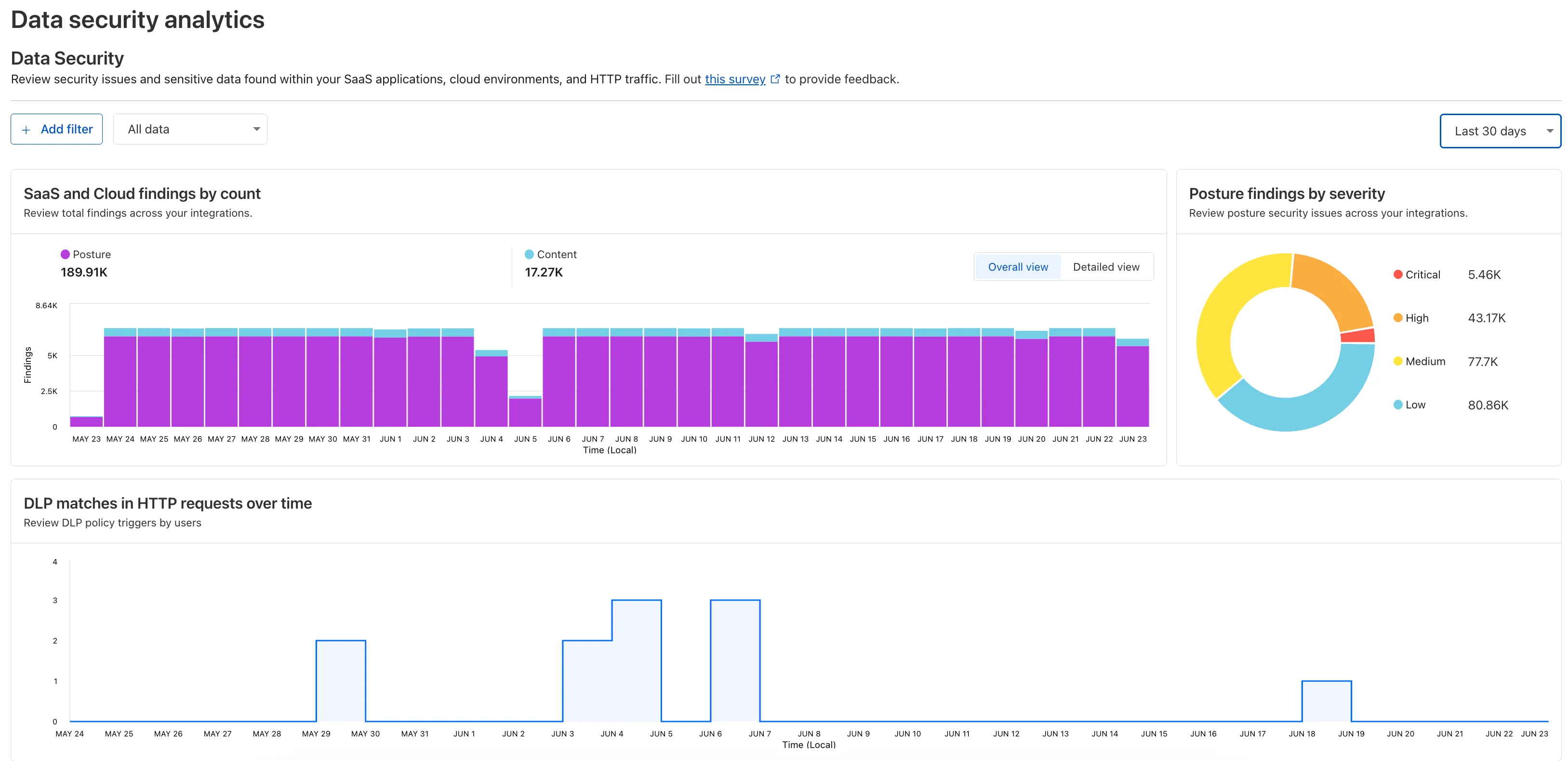
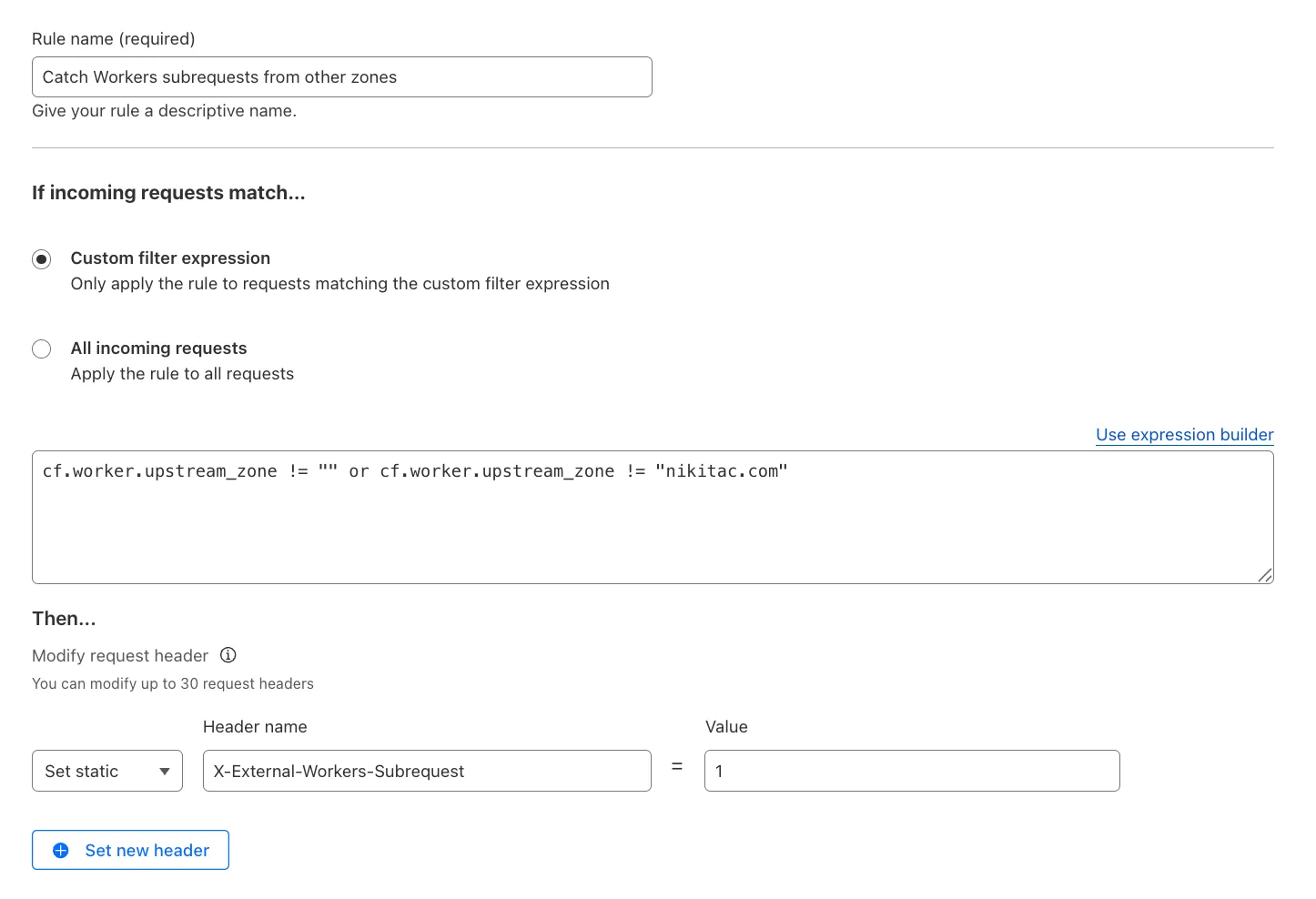
Text in Expression Editor (replace myappexample.com with your domain):
(cf.worker.upstream_zone != "" and cf.worker.upstream_zone != "myappexample.com")Selected operation under Modify request header: Set static
Header name: X-External-Workers-Subrequest
Value: 1