
Workers AI is excited to add 4 new models to the catalog, including 2 brand new classes of models with a text-to-speech and reranker model. Introducing:
- @cf/baai/bge-m3 - a multi-lingual embeddings model that supports over 100 languages. It can also simultaneously perform dense retrieval, multi-vector retrieval, and sparse retrieval, with the ability to process inputs of different granularities.
- @cf/baai/bge-reranker-base - our first reranker model! Rerankers are a type of text classification model that takes a query and context, and outputs a similarity score between the two. When used in RAG systems, you can use a reranker after the initial vector search to find the most relevant documents to return to a user by reranking the outputs.
- @cf/openai/whisper-large-v3-turbo - a faster, more accurate speech-to-text model. This model was added earlier but is graduating out of beta with pricing included today.
- @cf/myshell-ai/melotts - our first text-to-speech model that allows users to generate an MP3 with voice audio from inputted text.
Pricing is available for each of these models on the Workers AI pricing page.
This docs update includes a few minor bug fixes to the model schema for llama-guard, llama-3.2-1b, which you can review on the product changelog.
Try it out and let us know what you think! Stay tuned for more models in the coming days.
You can now access bindings from anywhere in your Worker by importing the
envobject fromcloudflare:workers.Previously,
envcould only be accessed during a request. This meant that bindings could not be used in the top-level context of a Worker.Now, you can import
envand access bindings such as secrets or environment variables in the initial setup for your Worker:JavaScript import { env } from "cloudflare:workers";import ApiClient from "example-api-client";// API_KEY and LOG_LEVEL now usable in top-level scopeconst apiClient = ApiClient.new({ apiKey: env.API_KEY });const LOG_LEVEL = env.LOG_LEVEL || "info";export default {fetch(req) {// you can use apiClient or LOG_LEVEL, configured before any request is handled},};Additionally,
envwas normally accessed as a argument to a Worker's entrypoint handler, such asfetch. This meant that if you needed to access a binding from a deeply nested function, you had to passenvas an argument through many functions to get it to the right spot. This could be cumbersome in complex codebases.Now, you can access the bindings from anywhere in your codebase without passing
envas an argument:JavaScript // helpers.jsimport { env } from "cloudflare:workers";// env is *not* an argument to this functionexport async function getValue(key) {let prefix = env.KV_PREFIX;return await env.KV.get(`${prefix}-${key}`);}For more information, see documentation on accessing
env.
You can now retry your Cloudflare Pages and Workers builds directly from GitHub. No need to switch to the Cloudflare Dashboard for a simple retry!
Let\u2019s say you push a commit, but your build fails due to a spurious error like a network timeout. Instead of going to the Cloudflare Dashboard to manually retry, you can now rerun the build with just a few clicks inside GitHub, keeping you inside your workflow.
For Pages and Workers projects connected to a GitHub repository:
- When a build fails, go to your GitHub repository or pull request
- Select the failed Check Run for the build
- Select "Details" on the Check Run
- Select "Rerun" to trigger a retry build for that commit
Learn more about Pages Builds and Workers Builds.
Magic Firewall now supports a new managed list of Cloudflare IP ranges. This list is available as an option when creating a Magic Firewall policy based on IP source/destination addresses. When selecting "is in list" or "is not in list", the option "Cloudflare IP Ranges" will appear in the dropdown menu.
This list is based on the IPs listed in the Cloudflare IP ranges ↗. Updates to this managed list are applied automatically.
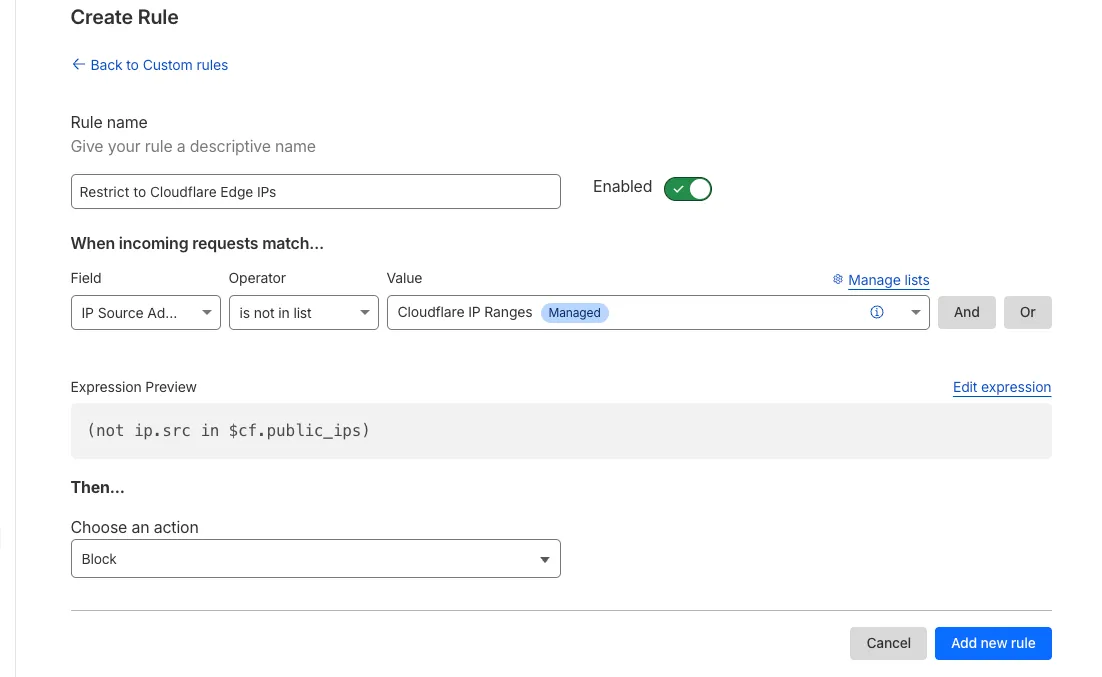
Note: IP Lists require a Cloudflare Advanced Network Firewall subscription. For more details about Cloudflare Network Firewall plans, refer to Plans.
We've released the next major version of Wrangler, the CLI for Cloudflare Workers —
wrangler@4.0.0. Wrangler v4 is a major release focused on updates to underlying systems and dependencies, along with improvements to keep Wrangler commands consistent and clear.You can run the following command to install it in your projects:
npm i wrangler@latestyarn add wrangler@latestpnpm add wrangler@latestbun add wrangler@latestUnlike previous major versions of Wrangler, which were foundational rewrites ↗ and rearchitectures ↗ — Version 4 of Wrangler includes a much smaller set of changes. If you use Wrangler today, your workflow is very unlikely to change.
A detailed migration guide is available and if you find a bug or hit a roadblock when upgrading to Wrangler v4, open an issue on the
cloudflare/workers-sdkrepository on GitHub ↗.Going forward, we'll continue supporting Wrangler v3 with bug fixes and security updates until Q1 2026, and with critical security updates until Q1 2027, at which point it will be out of support.
You can now debug your Workers tests with our Vitest integration by running the following command:
Terminal window vitest --inspect --no-file-parallelismAttach a debugger to the port 9229 and you can start stepping through your Workers tests. This is available with
@cloudflare/vitest-pool-workersv0.7.5 or later.Learn more in our documentation.
We’re removing some of the restrictions in Email Routing so that AI Agents and task automation can better handle email workflows, including how Workers can reply to incoming emails.
It's now possible to keep a threaded email conversation with an Email Worker script as long as:
- The incoming email has to have valid DMARC ↗.
- The email can only be replied to once in the same
EmailMessageevent. - The recipient in the reply must match the incoming sender.
- The outgoing sender domain must match the same domain that received the email.
- Every time an email passes through Email Routing or another MTA, an entry is added to the
Referenceslist. We stop accepting replies to emails with more than 100Referencesentries to prevent abuse or accidental loops.
Here's an example of a Worker responding to Emails using a Workers AI model:
AI model responding to emails import PostalMime from "postal-mime";import { createMimeMessage } from "mimetext";import { EmailMessage } from "cloudflare:email";export default {async email(message, env, ctx) {const email = await PostalMime.parse(message.raw);const res = await env.AI.run("@cf/meta/llama-2-7b-chat-fp16", {messages: [{role: "user",content: email.text ?? "",},],});// message-id is generated by mimetextconst response = createMimeMessage();response.setHeader("In-Reply-To", message.headers.get("Message-ID")!);response.setSender("agent@example.com");response.setRecipient(message.from);response.setSubject("Llama response");response.addMessage({contentType: "text/plain",data:res instanceof ReadableStream? await new Response(res).text(): res.response!,});const replyMessage = new EmailMessage("<email>",message.from,response.asRaw(),);await message.reply(replyMessage);},} satisfies ExportedHandler<Env>;See Reply to emails from Workers for more information.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset 100731 Apache Camel - Code Injection - CVE:CVE-2025-27636 N/A Block This is a New Detection
You can now access environment variables and secrets on
process.envwhen using thenodejs_compatcompatibility flag.JavaScript const apiClient = ApiClient.new({ apiKey: process.env.API_KEY });const LOG_LEVEL = process.env.LOG_LEVEL || "info";In Node.js, environment variables are exposed via the global
process.envobject. Some libraries assume that this object will be populated, and many developers may be used to accessing variables in this way.Previously, the
process.envobject was always empty unless written to in Worker code. This could cause unexpected errors or friction when developing Workers using code previously written for Node.js.Now, environment variables, secrets, and version metadata can all be accessed on
process.env.To opt-in to the new
process.envbehaviour now, add thenodejs_compat_populate_process_envcompatibility flag to yourwrangler.jsonconfiguration:JSONC {// Rest of your configuration// Add "nodejs_compat_populate_process_env" to your compatibility_flags array"compatibility_flags": ["nodejs_compat", "nodejs_compat_populate_process_env"],// Rest of your configurationTOML compatibility_flags = [ "nodejs_compat", "nodejs_compat_populate_process_env" ]After April 1, 2025, populating
process.envwill become the default behavior when bothnodejs_compatis enabled and your Worker'scompatibility_dateis after "2025-04-01".
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset 100722 Ivanti - Information Disclosure - CVE:CVE-2025-0282 Log Block This is a New Detection Cloudflare Managed Ruleset 100723 Cisco IOS XE - Information Disclosure - CVE:CVE-2023-20198 Log Block This is a New Detection
Digital Experience Monitoring (DEX) provides visibility into device, network, and application performance across your Cloudflare SASE deployment. The latest release of the Cloudflare One agent (v2025.1.861) now includes device endpoint monitoring capabilities to provide deeper visibility into end-user device performance which can be analyzed directly from the dashboard.
Device health metrics are now automatically collected, allowing administrators to:
- View the last network a user was connected to
- Monitor CPU and RAM utilization on devices
- Identify resource-intensive processes running on endpoints
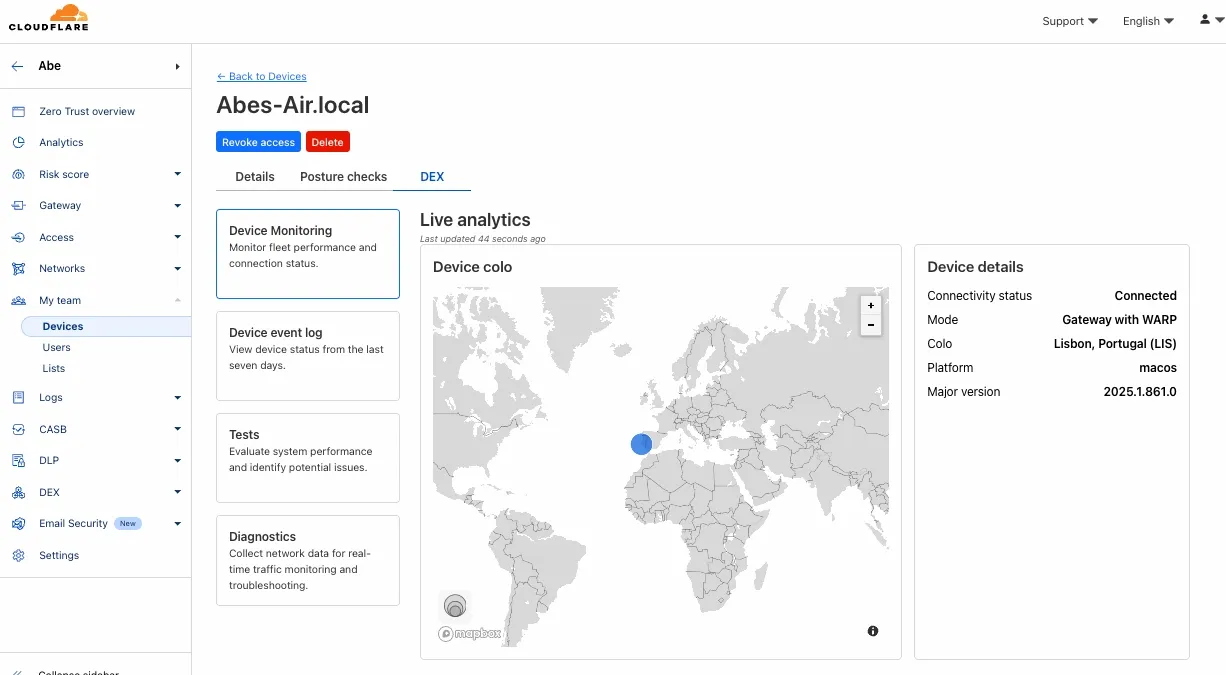
This feature complements existing DEX features like synthetic application monitoring and network path visualization, creating a comprehensive troubleshooting workflow that connects application performance with device state.
For more details refer to our DEX documentation.
Hyperdrive now pools database connections in one or more regions close to your database. This means that your uncached queries and new database connections have up to 90% less latency as measured from connection pools.
By improving placement of Hyperdrive database connection pools, Workers' Smart Placement is now more effective when used with Hyperdrive, ensuring that your Worker can be placed as close to your database as possible.
With this update, Hyperdrive also uses Cloudflare's standard IP address ranges ↗ to connect to your database. This enables you to configure the firewall policies (IP access control lists) of your database to only allow access from Cloudflare and Hyperdrive.
Refer to documentation on how Hyperdrive makes connecting to regional databases from Cloudflare Workers fast.
This improvement is enabled on all Hyperdrive configurations.
Added new records to the leaked credentials database. The record sources are: Have I Been Pwned (HIBP) database, RockYou 2024 dataset, and another third-party database.
We’ve streamlined the Logpush setup process by integrating R2 bucket creation directly into the Logpush workflow!
Now, you no longer need to navigate multiple pages to manually create an R2 bucket or copy credentials. With this update, you can seamlessly configure a Logpush job to R2 in just one click, reducing friction and making setup faster and easier.
This enhancement makes it easier for customers to adopt Logpush and R2.
For more details refer to our Logs documentation.
You can now use bucket locks to set retention policies on your R2 buckets (or specific prefixes within your buckets) for a specified period — or indefinitely. This can help ensure compliance by protecting important data from accidental or malicious deletion.
Locks give you a few ways to ensure your objects are retained (not deleted or overwritten). You can:
- Lock objects for a specific duration, for example 90 days.
- Lock objects until a certain date, for example January 1, 2030.
- Lock objects indefinitely, until the lock is explicitly removed.
Buckets can have up to 1,000 bucket lock rules. Each rule specifies which objects it covers (via prefix) and how long those objects must remain retained.
Here are a couple of examples showing how you can configure bucket lock rules using Wrangler:
Terminal window npx wrangler r2 bucket lock add <bucket> --name 180-days-all --retention-days 180Terminal window npx wrangler r2 bucket lock add <bucket> --name indefinite-logs --prefix logs/ --retention-indefiniteFor more information on bucket locks and how to set retention policies for objects in your R2 buckets, refer to our documentation.
Today, we are thrilled to announce Media Transformations, a new service that brings the magic of Image Transformations to short-form video files, wherever they are stored!
For customers with a huge volume of short video — generative AI output, e-commerce product videos, social media clips, or short marketing content — uploading those assets to Stream is not always practical. Sometimes, the greatest friction to getting started was the thought of all that migrating. Customers want a simpler solution that retains their current storage strategy to deliver small, optimized MP4 files. Now you can do that with Media Transformations.
To transform a video or image, enable transformations for your zone, then make a simple request with a specially formatted URL. The result is an MP4 that can be used in an HTML video element without a player library. If your zone already has Image Transformations enabled, then it is ready to optimize videos with Media Transformations, too.
URL format https://example.com/cdn-cgi/media/<OPTIONS>/<SOURCE-VIDEO>For example, we have a short video of the mobile in Austin's office. The original is nearly 30 megabytes and wider than necessary for this layout. Consider a simple width adjustment:
Example URL https://example.com/cdn-cgi/media/width=640/<SOURCE-VIDEO>https://developers.cloudflare.com/cdn-cgi/media/width=640/https://pub-d9fcbc1abcd244c1821f38b99017347f.r2.dev/aus-mobile.mp4The result is less than 3 megabytes, properly sized, and delivered dynamically so that customers do not have to manage the creation and storage of these transformed assets.
For more information, learn about Transforming Videos.
We're excited to announce that new logging capabilities for Remote Browser Isolation (RBI) through Logpush are available in Beta starting today!
With these enhanced logs, administrators can gain visibility into end user behavior in the remote browser and track blocked data extraction attempts, along with the websites that triggered them, in an isolated session.
{"AccountID": "$ACCOUNT_ID","Decision": "block","DomainName": "www.example.com","Timestamp": "2025-02-27T23:15:06Z","Type": "copy","UserID": "$USER_ID"}User Actions available:
- Copy & Paste
- Downloads & Uploads
- Printing
Learn more about how to get started with Logpush in our documentation.
Access for SaaS applications now include more configuration options to support a wider array of SaaS applications.
SAML and OIDC Field Additions
OIDC apps now include:
- Group Filtering via RegEx
- OIDC Claim mapping from an IdP
- OIDC token lifetime control
- Advanced OIDC auth flows including hybrid and implicit flows

SAML apps now include improved SAML attribute mapping from an IdP.

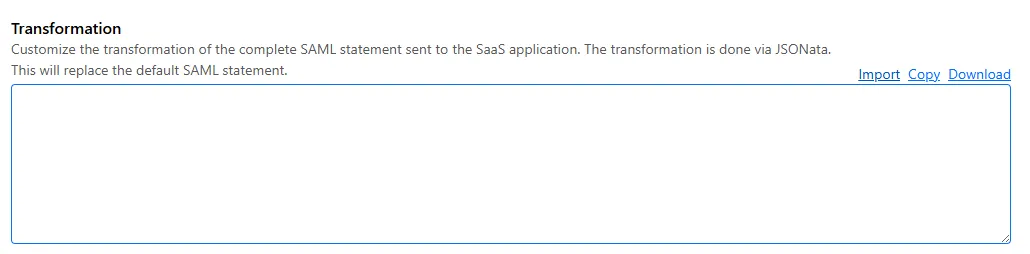
SAML transformations
SAML identities sent to Access applications can be fully customized using JSONata expressions. This allows admins to configure the precise identity SAML statement sent to a SaaS application.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset 100721 Ivanti - Remote Code Execution - CVE:CVE-2024-13159, CVE:CVE-2024-13160, CVE:CVE-2024-13161
Log Block This is a New Detection Cloudflare Managed Ruleset 100596 Citrix Content Collaboration ShareFile - Remote Code Execution - CVE:CVE-2023-24489
N/A Block
You can now send detection logs to an endpoint of your choice with Cloudflare Logpush.
Filter logs matching specific criteria you have set and select from over 25 fields you want to send. When creating a new Logpush job, remember to select Email security alerts as the dataset.
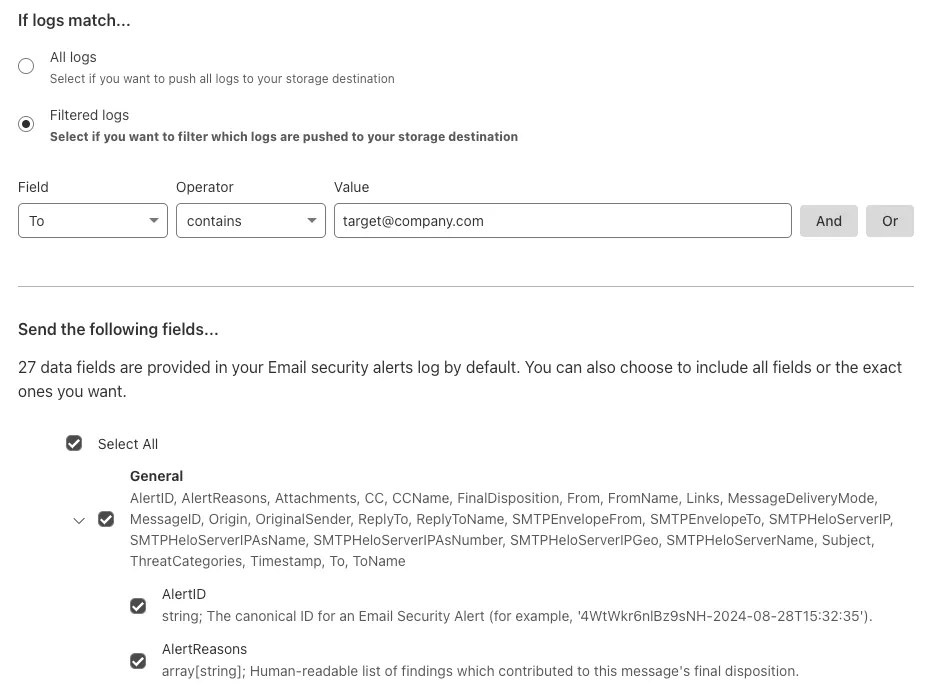
For more information, refer to Enable detection logs.
This feature is available across these Email security packages:
- Enterprise
- Enterprise + PhishGuard
We've released a release candidate of the next major version of Wrangler, the CLI for Cloudflare Workers —
wrangler@4.0.0-rc.0.You can run the following command to install it and be one of the first to try it out:
npm i wrangler@v4-rcyarn add wrangler@v4-rcpnpm add wrangler@v4-rcbun add wrangler@v4-rcUnlike previous major versions of Wrangler, which were foundational rewrites ↗ and rearchitectures ↗ — Version 4 of Wrangler includes a much smaller set of changes. If you use Wrangler today, your workflow is very unlikely to change. Before we release Wrangler v4 and advance past the release candidate stage, we'll share a detailed migration guide in the Workers developer docs. But for the vast majority of cases, you won't need to do anything to migrate — things will just work as they do today. We are sharing this release candidate in advance of the official release of v4, so that you can try it out early and share feedback.
Version 4 of Wrangler updates the version of esbuild ↗ that Wrangler uses internally, allowing you to use modern JavaScript language features, including:
The
usingkeyword from the Explicit Resource Management standard makes it easier to work with the JavaScript-native RPC system built into Workers. This means that when you obtain a stub, you can ensure that it is automatically disposed when you exit scope it was created in:JavaScript function sendEmail(id, message) {using user = await env.USER_SERVICE.findUser(id);await user.sendEmail(message);// user[Symbol.dispose]() is implicitly called at the end of the scope.}Import attributes ↗ allow you to denote the type or other attributes of the module that your code imports. For example, you can import a JSON module, using the following syntax:
JavaScript import data from "./data.json" with { type: "json" };All commands that access resources (for example,
wrangler kv,wrangler r2,wrangler d1) now access local datastores by default, ensuring consistent behavior.Moving forward, the active, maintenance, and current versions of Node.js ↗ will be officially supported by Wrangler. This means the minimum officially supported version of Node.js you must have installed for Wrangler v4 will be Node.js v18 or later. This policy mirrors how many other packages and CLIs support older versions of Node.js, and ensures that as long as you are using a version of Node.js that the Node.js project itself supports, this will be supported by Wrangler as well.
All previously deprecated features in Wrangler v2 ↗ and in Wrangler v3 ↗ have now been removed. Additionally, the following features that were deprecated during the Wrangler v3 release have been removed:
- Legacy Assets (using
wrangler dev/deploy --legacy-assetsor thelegacy_assetsconfig file property). Instead, we recommend you migrate to Workers assets ↗. - Legacy Node.js compatibility (using
wrangler dev/deploy --node-compator thenode_compatconfig file property). Instead, use thenodejs_compatcompatibility flag ↗. This includes the functionality from legacynode_compatpolyfills and natively implemented Node.js APIs. wrangler version. Instead, usewrangler --versionto check the current version of Wrangler.getBindingsProxy()(viaimport { getBindingsProxy } from "wrangler"). Instead, use thegetPlatformProxy()API ↗, which takes exactly the same arguments.usage_model. This no longer has any effect, after the rollout of Workers Standard Pricing ↗.
We'd love your feedback! If you find a bug or hit a roadblock when upgrading to Wrangler v4, open an issue on the
cloudflare/workers-sdkrepository on GitHub ↗.- Legacy Assets (using
Concerns about performance for Email security or Area 1? You can now check the operational status of both on the Cloudflare Status page ↗.
For Email security, look under Cloudflare Sites and Services.
- Dashboard is the dashboard for Cloudflare, including Email security
- Email security (Zero Trust) is the processing of email
- API are the Cloudflare endpoints, including the ones for Email security
For Area 1, under Cloudflare Sites and Services:
- Area 1 - Dash is the dashboard for Cloudflare, including Email security
- Email security (Area1) is the processing of email
- Area 1 - API are the Area 1 endpoints

This feature is available across these Email security packages:
- Advantage
- Enterprise
- Enterprise + PhishGuard
We've released a new REST API for Browser Rendering in open beta, making interacting with browsers easier than ever. This new API provides endpoints for common browser actions, with more to be added in the future.
With the REST API you can:
- Capture screenshots – Use
/screenshotto take a screenshot of a webpage from provided URL or HTML. - Generate PDFs – Use
/pdfto convert web pages into PDFs. - Extract HTML content – Use
/contentto retrieve the full HTML from a page. Snapshot (HTML + Screenshot) – Use/snapshotto capture both the page's HTML and a screenshot in one request - Scrape Web Elements – Use
/scrapeto extract specific elements from a page.
For example, to capture a screenshot:
Screenshot example curl -X POST 'https://api.cloudflare.com/client/v4/accounts/<accountId>/browser-rendering/screenshot' \-H 'Authorization: Bearer <apiToken>' \-H 'Content-Type: application/json' \-d '{"html": "Hello World!","screenshotOptions": {"type": "webp","omitBackground": true}}' \--output "screenshot.webp"Learn more in our documentation.
- Capture screenshots – Use
Radar has expanded its DNS insights, providing visibility into aggregated traffic and usage trends observed by our 1.1.1.1 DNS resolver. In addition to global, location, and ASN traffic trends, we are also providing perspectives on protocol usage, query/response characteristics, and DNSSEC usage.
Previously limited to the
toplocations and ASes endpoints, we have now introduced the following endpoints:/dns/timeseries: Retrieves DNS query volume over time./dns/summary/{dimension}: Retrieves summaries of DNS query distribution across ten different dimensions./dns/timeseries_groups/{dimension}: Retrieves timeseries data for DNS query distribution across ten different dimensions.
For the
summaryandtimeseries_groupsendpoints, the following dimensions are available, displaying the distribution of DNS queries based on:cache_hit: Cache status (hit vs. miss).dnsssec: DNSSEC support status (secure, insecure, invalid or other).dnsssec_aware: DNSSEC client awareness (aware vs. not-aware).dnsssec_e2e: End-to-end security (secure vs. insecure).ip_version: IP version (IPv4 vs. IPv6).matching_answer: Matching answer status (match vs. no-match).protocol: Transport protocol (UDP, TLS, HTTPS or TCP).query_type: Query type (A,AAAA,PTR, etc.).response_code: Response code (NOERROR,NXDOMAIN,REFUSED, etc.).response_ttl: Response TTL.
Learn more about the new Radar DNS insights in our blog post ↗, and check out the new Radar page ↗.
AI Gateway now includes Guardrails, to help you monitor your AI apps for harmful or inappropriate content and deploy safely.
Within the AI Gateway settings, you can configure:
- Guardrails: Enable or disable content moderation as needed.
- Evaluation scope: Select whether to moderate user prompts, model responses, or both.
- Hazard categories: Specify which categories to monitor and determine whether detected inappropriate content should be blocked or flagged.

Learn more in the blog ↗ or our documentation.