
The
@cloudflare/codemode↗ package has been rewritten into a modular, runtime-agnostic SDK.Code Mode ↗ enables LLMs to write and execute code that orchestrates your tools, instead of calling them one at a time. This can (and does) yield significant token savings, reduces context window pressure and improves overall model performance on a task.
The new
Executorinterface is runtime agnostic and comes with a prebuiltDynamicWorkerExecutorto run generated code in a Dynamic Worker Loader.- Removed
experimental_codemode()andCodeModeProxy— the package no longer owns an LLM call or model choice - New import path:
createCodeTool()is now exported from@cloudflare/codemode/ai
createCodeTool()— Returns a standard AI SDKToolto use in your AI agents.Executorinterface — Minimalexecute(code, fns)contract. Implement for any code sandboxing primitive or runtime.
Runs code in a Dynamic Worker. It comes with the following features:
- Network isolation —
fetch()andconnect()blocked by default (globalOutbound: null) when usingDynamicWorkerExecutor - Console capture —
console.log/warn/errorcaptured and returned inExecuteResult.logs - Execution timeout — Configurable via
timeoutoption (default 30s)
JavaScript import { createCodeTool } from "@cloudflare/codemode/ai";import { DynamicWorkerExecutor } from "@cloudflare/codemode";import { streamText } from "ai";const executor = new DynamicWorkerExecutor({ loader: env.LOADER });const codemode = createCodeTool({ tools: myTools, executor });const result = streamText({model,tools: { codemode },messages,});TypeScript import { createCodeTool } from "@cloudflare/codemode/ai";import { DynamicWorkerExecutor } from "@cloudflare/codemode";import { streamText } from "ai";const executor = new DynamicWorkerExecutor({ loader: env.LOADER });const codemode = createCodeTool({ tools: myTools, executor });const result = streamText({model,tools: { codemode },messages,});JSONC {"worker_loaders": [{ "binding": "LOADER" }],}TOML [[worker_loaders]]binding = "LOADER"See the Code Mode documentation for full API reference and examples.
Terminal window npm i @cloudflare/codemode@latest- Removed
You can now easily understand your SaaS security posture findings and why they were detected with Cloudy Summaries in CASB. This feature integrates Cloudflare's Cloudy AI directly into your CASB Posture Findings to automatically generate clear, plain-language summaries of complex security misconfigurations, third-party app risks, and data exposures.
This allows security teams and IT administrators to drastically reduce triage time by immediately understanding the context, potential impact, and necessary remediation steps for any given finding—without needing to be an expert in every connected SaaS application.
To view a summary, simply navigate to your Posture Findings in the Cloudflare One dashboard (under Cloud and SaaS findings) and open the finding details of a specific instance of a Finding.
Cloudy Summaries are supported on all available integrations, including Microsoft 365, Google Workspace, Salesforce, GitHub, AWS, Slack, and Dropbox. See the full list of supported integrations here.
- Contextual explanations — Quickly understand the specifics of a finding with plain-language summaries detailing exactly what was detected, from publicly shared sensitive files to risky third-party app scopes.
- Clear risk assessment — Instantly grasp the potential security impact of the finding, such as data breach risks, unauthorized account access, or email spoofing vulnerabilities.
- Actionable guidance — Get clear recommendations and next steps on how to effectively remediate the issue and secure your environment.
- Built-in feedback — Help improve future AI summarization accuracy by submitting feedback directly using the thumbs-up and thumbs-down buttons.
- Learn more about managing CASB Posture Findings in Cloudflare.
Cloudy Summaries in CASB are available to all Cloudflare CASB users today.
Cloudflare Tunnel is now available in the main Cloudflare Dashboard at Networking > Tunnels ↗, bringing first-class Tunnel management to developers using Tunnel for securing origin servers.
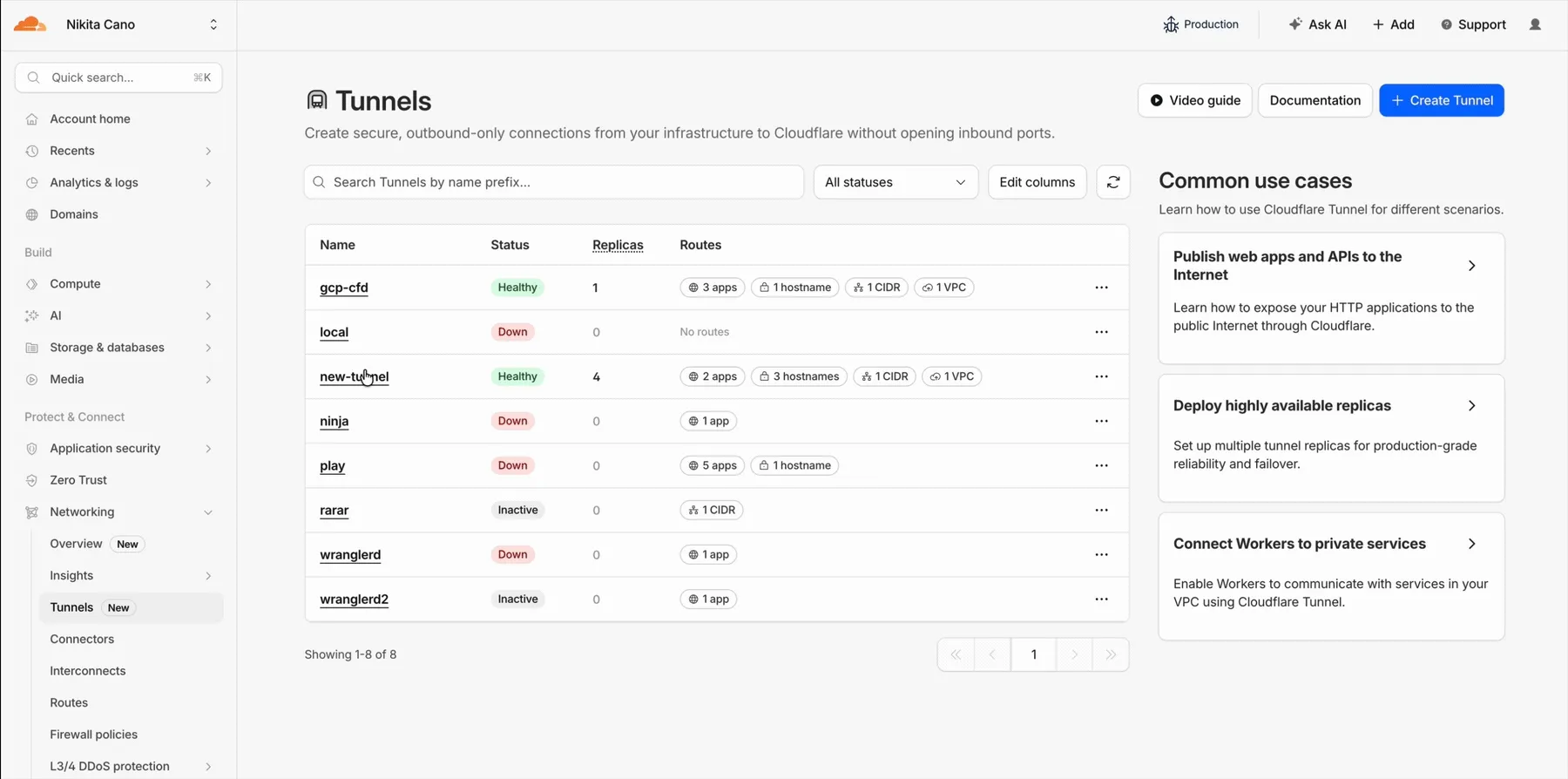
This new experience provides everything you need to manage Tunnels for public applications, including:
- Full Tunnel lifecycle management: Create, configure, delete, and monitor all your Tunnels in one place.
- Native integrations: View Tunnels by name when configuring DNS records and Workers VPC — no more copy-pasting UUIDs.
- Real-time visibility: Monitor replicas and Tunnel health status directly in the dashboard.
- Routing map: Manage all ingress routes for your Tunnel, including public applications, private hostnames, private CIDRs, and Workers VPC services, from a single interactive interface.
Core Dashboard: Navigate to Networking > Tunnels ↗ to manage Tunnels for:
- Securing origin servers and public applications with CDN, WAF, Load Balancing, and DDoS protection
- Connecting Workers to private services via Workers VPC
Cloudflare One Dashboard: Navigate to Zero Trust > Networks > Connectors ↗ to manage Tunnels for:
- Securing your public applications with Zero Trust access policies
- Connecting users to private applications
- Building a private mesh network
Both dashboards provide complete Tunnel management capabilities — choose based on your primary workflow.
New to Tunnel? Learn how to get started with Cloudflare Tunnel or explore advanced use cases like securing SSH servers or running Tunnels in Kubernetes.
Workers AI and AI Gateway have received a series of dashboard improvements to help you get started faster and manage your AI workloads more easily.
Navigation and discoverability
AI now has its own top-level section in the Cloudflare dashboard sidebar, so you can find AI features without digging through menus.
Onboarding and getting started
Getting started with AI Gateway is now simpler. When you create your first gateway, we now show your gateway's OpenAI-compatible endpoint and step-by-step guidance to help you configure it. The Playground also includes helpful prompts, and usage pages have clear next steps if you have not made any requests yet.
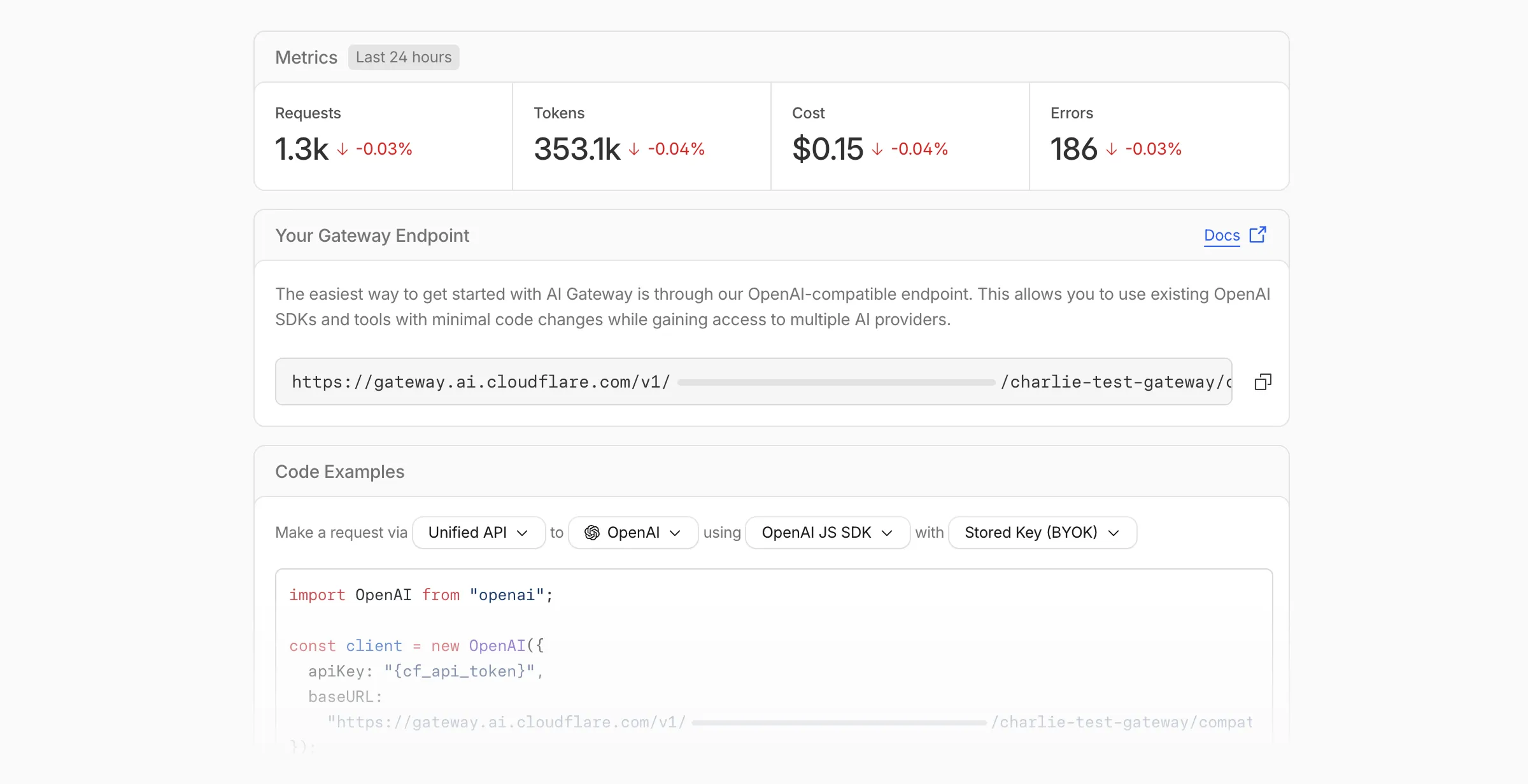
We've also combined the previously separate code example sections into one view with dropdown selectors for API type, provider, SDK, and authentication method so you can now customize the exact code snippet you need from one place.
Dynamic Routing
- The route builder is now more performant and responsive.
- You can now copy route names to your clipboard with a single click.
- Code examples use the Universal Endpoint format, making it easier to integrate routes into your application.
Observability and analytics
- Small monetary values now display correctly in cost analytics charts, so you can accurately track spending at any scale.
Accessibility
- Improvements to keyboard navigation within the AI Gateway, specifically when exploring usage by provider.
- Improvements to sorting and filtering components on the Workers AI models page.
For more information, refer to the AI Gateway documentation.
Digital Experience Monitoring (DEX) provides visibility into WARP device connectivity and performance to any internal or external application.
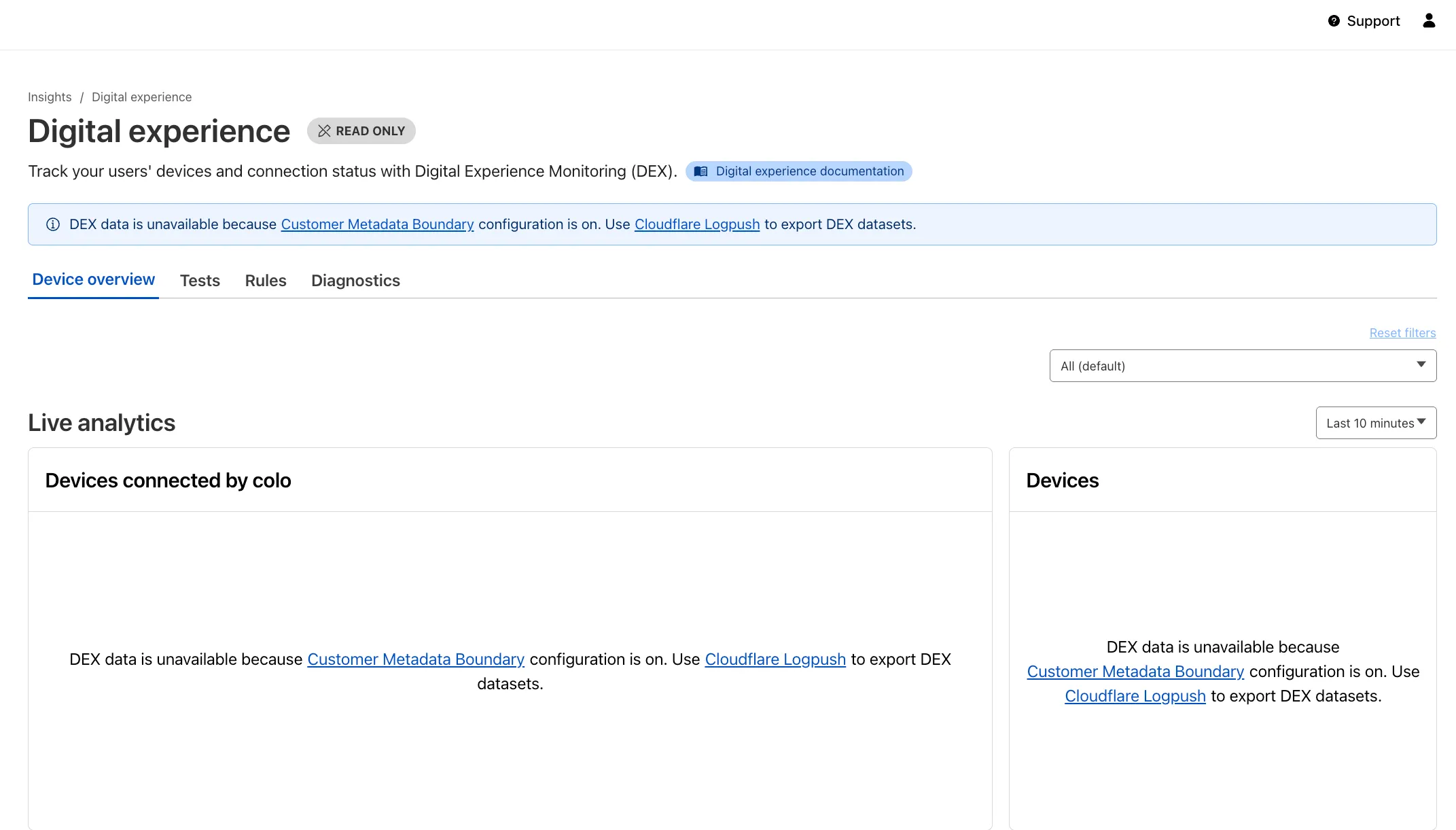
Now, all DEX logs are fully compatible with Cloudflare's Customer Metadata Boundary (CMB) setting for the 'EU' (European Union), which ensures that DEX logs will not be stored outside the 'EU' when the option is configured.
If a Cloudflare One customer using DEX enables CMB 'EU', they will not see any DEX data in the Cloudflare One dashboard. Customers can ingest DEX data via LogPush, and build their own analytics and dashboards.
If a customer enables CMB in their account, they will see the following message in the Digital Experience dashboard: "DEX data is unavailable because Customer Metadata Boundary configuration is on. Use Cloudflare LogPush to export DEX datasets."
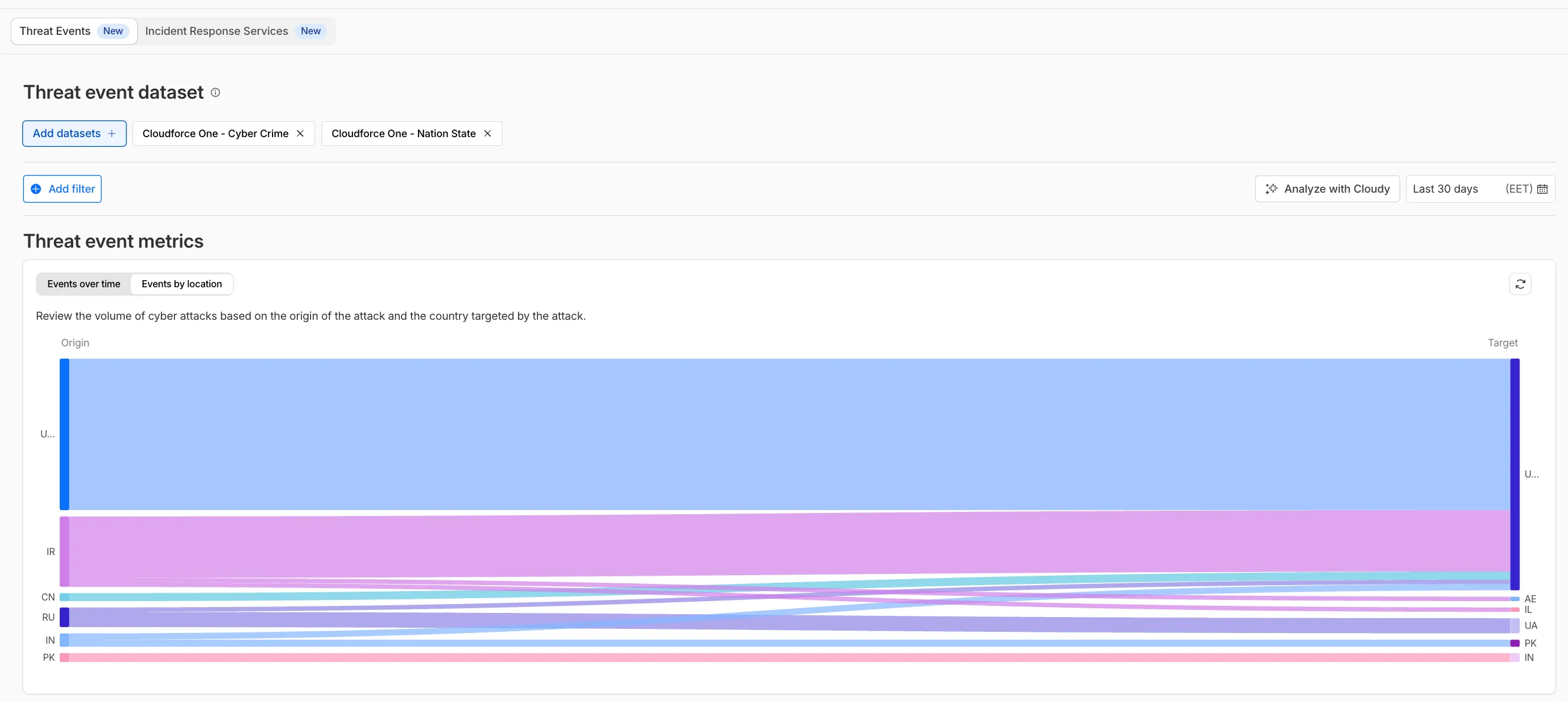
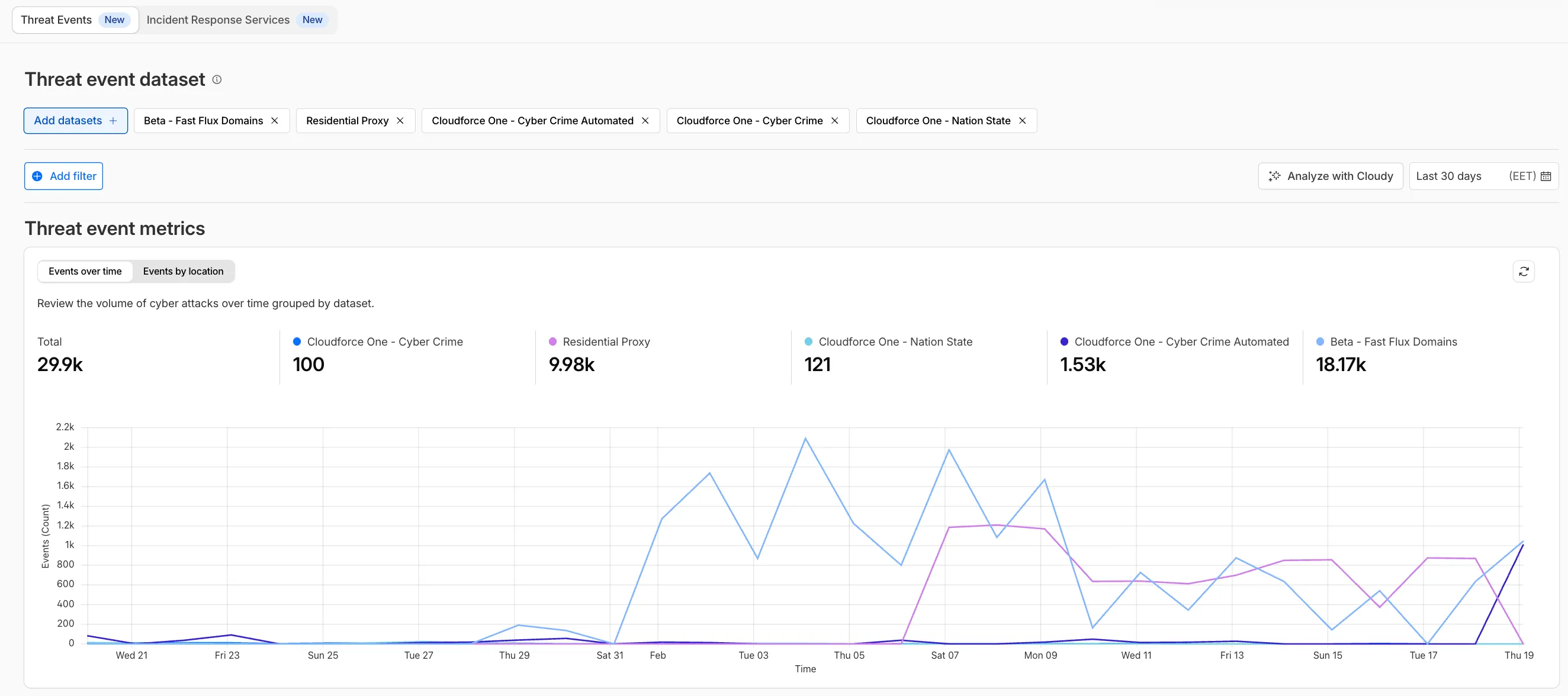
We have introduced dynamic visualizations to the Threat Events dashboard to help you better understand the threat landscape and identify emerging patterns at a glance.
What's new:
- Sankey Diagrams: Trace the flow of attacks from country of origin to target country to identify which regions are being hit hardest and where the threat infrastructure resides.
- Dataset Distribution over time: Instantly pivot your view to understand if a specific campaign is targeting your sector or if it is a broad-spectrum commodity attack.
- Enhanced Filtering: Use these visual tools to filter and drill down into specific attack vectors directly from the charts.
Cloudforce One subscribers can explore these new views now in Application Security > Threat Intelligence > Threat Events ↗.
The Server-Timing header now includes a new
cfWorkermetric that measures time spent executing Cloudflare Workers, including any subrequests performed by the Worker. This helps developers accurately identify whether high Time to First Byte (TTFB) is caused by Worker processing or slow upstream dependencies.Previously, Worker execution time was included in the
edgemetric, making it harder to identify true edge performance. The newcfWorkermetric provides this visibility:Metric Description edgeTotal time spent on the Cloudflare edge, including Worker execution originTime spent fetching from the origin server cfWorkerTime spent in Worker execution, including subrequests but excluding origin fetch time Server-Timing: cdn-cache; desc=DYNAMIC, edge; dur=20, origin; dur=100, cfWorker; dur=7In this example, the edge took 20ms, the origin took 100ms, and the Worker added just 7ms of processing time.
The
cfWorkermetric is enabled by default if you have Real User Monitoring (RUM) enabled. Otherwise, you can enable it using Rules.This metric is particularly useful for:
- Performance debugging: Quickly determine if latency is caused by Worker code, external API calls within Workers, or slow origins.
- Optimization targeting: Identify which component of your request path needs optimization.
- Real User Monitoring (RUM): Access detailed timing breakdowns directly from response headers for client-side analytics.
For more information about Server-Timing headers, refer to the W3C Server Timing specification ↗.
A new Allow clientless access setting makes it easier to connect users without a device client to internal applications, without using public DNS.

Previously, to provide clientless access to a private hostname or IP without a published application, you had to create a separate bookmark application pointing to a prefixed Clientless Web Isolation URL (for example,
https://<your-teamname>.cloudflareaccess.com/browser/https://10.0.0.1/). This bookmark was visible to all users in the App Launcher, regardless of whether they had access to the underlying application.Now, you can manage clientless access directly within your private self-hosted application. When Allow clientless access is turned on, users who pass your Access application policies will see a tile in their App Launcher pointing to the prefixed URL. Users must have remote browser permissions to open the link.
You can now assign Access policies to bookmark applications. This lets you control which users see a bookmark in the App Launcher based on identity, device posture, and other policy rules.
Previously, bookmark applications were visible to all users in your organization. With policy support, you can now:
- Tailor the App Launcher to each user — Users only see the applications they have access to, reducing clutter and preventing accidental clicks on irrelevant resources.
- Restrict visibility of sensitive bookmarks — Limit who can view bookmarks to internal tools or partner resources based on group membership, identity provider, or device posture.
Bookmarks support all Access policy configurations except purpose justification, temporary authentication, and application isolation. If no policy is assigned, the bookmark remains visible to all users (maintaining backwards compatibility).
For more information, refer to Add bookmarks.
The latest release of the Agents SDK ↗ adds built-in retry utilities, per-connection protocol message control, and a fully rewritten
@cloudflare/ai-chatwith data parts, tool approval persistence, and zero breaking changes.A new
this.retry()method lets you retry any async operation with exponential backoff and jitter. You can pass an optionalshouldRetrypredicate to bail early on non-retryable errors.JavaScript class MyAgent extends Agent {async onRequest(request) {const data = await this.retry(() => callUnreliableService(), {maxAttempts: 4,shouldRetry: (err) => !(err instanceof PermanentError),});return Response.json(data);}}TypeScript class MyAgent extends Agent {async onRequest(request: Request) {const data = await this.retry(() => callUnreliableService(), {maxAttempts: 4,shouldRetry: (err) => !(err instanceof PermanentError),});return Response.json(data);}}Retry options are also available per-task on
queue(),schedule(),scheduleEvery(), andaddMcpServer():JavaScript // Per-task retry configuration, persisted in SQLite alongside the taskawait this.schedule(Date.now() + 60_000,"sendReport",{ userId: "abc" },{retry: { maxAttempts: 5 },},);// Class-level retry defaultsclass MyAgent extends Agent {static options = {retry: { maxAttempts: 3 },};}TypeScript // Per-task retry configuration, persisted in SQLite alongside the taskawait this.schedule(Date.now() + 60_000, "sendReport", { userId: "abc" }, {retry: { maxAttempts: 5 },});// Class-level retry defaultsclass MyAgent extends Agent {static options = {retry: { maxAttempts: 3 },};}Retry options are validated eagerly at enqueue/schedule time, and invalid values throw immediately. Internal retries have also been added for workflow operations (
terminateWorkflow,pauseWorkflow, and others) with Durable Object-aware error detection.Agents automatically send JSON text frames (identity, state, MCP server lists) to every WebSocket connection. You can now suppress these per-connection for clients that cannot handle them — binary-only devices, MQTT clients, or lightweight embedded systems.
JavaScript class MyAgent extends Agent {shouldSendProtocolMessages(connection, ctx) {// Suppress protocol messages for MQTT clientsconst subprotocol = ctx.request.headers.get("Sec-WebSocket-Protocol");return subprotocol !== "mqtt";}}TypeScript class MyAgent extends Agent {shouldSendProtocolMessages(connection: Connection, ctx: ConnectionContext) {// Suppress protocol messages for MQTT clientsconst subprotocol = ctx.request.headers.get("Sec-WebSocket-Protocol");return subprotocol !== "mqtt";}}Connections with protocol messages disabled still fully participate in RPC and regular messaging. Use
isConnectionProtocolEnabled(connection)to check a connection's status at any time. The flag persists across Durable Object hibernation.See Protocol messages for full documentation.
The first stable release of
@cloudflare/ai-chatships alongside this release with a major refactor ofAIChatAgentinternals — newResumableStreamclass, WebSocketChatTransport, and simplified SSE parsing — with zero breaking changes. Existing code usingAIChatAgentanduseAgentChatworks as-is.Key new features:
- Data parts — Attach typed JSON blobs (
data-*) to messages alongside text. Supports reconciliation (type+id updates in-place), append, and transient parts (ephemeral viaonDatacallback). See Data parts. - Tool approval persistence — The
needsApprovalapproval UI now survives page refresh and DO hibernation. The streaming message is persisted to SQLite when a tool entersapproval-requestedstate. maxPersistedMessages— Cap SQLite message storage with automatic oldest-message deletion.bodyoption onuseAgentChat— Send custom data with every request (static or dynamic).- Incremental persistence — Hash-based cache to skip redundant SQL writes.
- Row size guard — Automatic two-pass compaction when messages approach the SQLite 2 MB limit.
autoContinueAfterToolResultdefaults totrue— Client-side tool results and tool approvals now automatically trigger a server continuation, matching server-executed tool behavior. SetautoContinueAfterToolResult: falseinuseAgentChatto restore the previous behavior.
Notable bug fixes:
- Resolved stream resumption race conditions
- Resolved an issue where
setMessagesfunctional updater sent empty arrays - Resolved an issue where client tool schemas were lost after DO hibernation
- Resolved
InvalidPromptErrorafter tool approval (approval.idwas dropped) - Resolved an issue where message metadata was not propagated on broadcast/resume paths
- Resolved an issue where
clearAll()did not clear in-memory chunk buffers - Resolved an issue where
reasoning-deltasilently dropped data whenreasoning-startwas missed during stream resumption
getQueue(),getQueues(),getSchedule(),dequeue(),dequeueAll(), anddequeueAllByCallback()were unnecessarilyasyncdespite only performing synchronous SQL operations. They now return values directly instead of wrapping them in Promises. This is backward compatible — existing code usingawaiton these methods will continue to work.- Fix TypeScript "excessively deep" error — A depth counter on
CanSerializeandIsSerializableParamtypes bails out totrueafter 10 levels of recursion, preventing the "Type instantiation is excessively deep" error with deeply nested types like AI SDKCoreMessage[]. - POST SSE keepalive — The POST SSE handler now sends
event: pingevery 30 seconds to keep the connection alive, matching the existing GET SSE handler behavior. This prevents POST response streams from being silently dropped by proxies during long-running tool calls. - Widened peer dependency ranges — Peer dependency ranges across packages have been widened to prevent cascading major bumps during 0.x minor releases.
@cloudflare/ai-chatand@cloudflare/codemodeare now marked as optional peer dependencies.
To update to the latest version:
Terminal window npm i agents@latest @cloudflare/ai-chat@latest- Data parts — Attach typed JSON blobs (
We are updating naming related to some of our Networking products to better clarify their place in the Zero Trust and Secure Access Service Edge (SASE) journey.
We are retiring some older brand names in favor of names that describe exactly what the products do within your network. We are doing this to help customers build better, clearer mental models for comprehensive SASE architecture delivered on Cloudflare.
- Magic WAN → Cloudflare WAN
- Magic WAN IPsec → Cloudflare IPsec
- Magic WAN GRE → Cloudflare GRE
- Magic WAN Connector → Cloudflare One Appliance
- Magic Firewall → Cloudflare Network Firewall
- Magic Network Monitoring → Network Flow
- Magic Cloud Networking → Cloudflare One Multi-cloud Networking
No action is required by you — all functionality, existing configurations, and billing will remain exactly the same.
For more information, visit the Cloudflare One documentation.
Sandboxes and Containers now support running Docker for "Docker-in-Docker" setups. This is particularly useful when your end users or agents want to run a full sandboxed development environment.
This allows you to:
- Develop containerized applications with your Sandbox
- Run isolated test environments for images
- Build container images as part of CI/CD workflows
- Deploy arbitrary images supplied at runtime within a container
For Sandbox SDK users, see the Docker-in-Docker guide for instructions on combining Docker with the SandboxSDK. For general Containers usage, see the Containers FAQ.
When AI systems request pages from any website that uses Cloudflare and has Markdown for Agents enabled, they can express the preference for
text/markdownin the request: our network will automatically and efficiently convert the HTML to markdown, when possible, on the fly.This release adds the following improvements:
- The origin response limit was raised from 1 MB to 2 MB (2,097,152 bytes).
- We no longer require the origin to send the
content-lengthheader. - We now support content encoded responses from the origin.
If you haven’t enabled automatic Markdown conversion yet, visit the AI Crawl Control ↗ section of the Cloudflare dashboard and enable Markdown for Agents.
Refer to our developer documentation for more details.
This week’s release introduces new detections for CVE-2025-68645 and CVE-2025-31125.
Key Findings
- CVE-2025-68645: A Local File Inclusion (LFI) vulnerability in the Webmail Classic UI of Zimbra Collaboration Suite (ZCS) 10.0 and 10.1 allows unauthenticated remote attackers to craft requests to the
/h/restendpoint, improperly influence internal dispatching, and include arbitrary files from the WebRoot directory. - CVE-2025-31125: Vite, the JavaScript frontend tooling framework, exposes content of non-allowed files via
?inline&importwhen its development server is network-exposed, enabling unauthorized attackers to read arbitrary files and potentially leak sensitive information.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset N/A Zimbra - Local File Inclusion - CVE:CVE-2025-68645 Log Block This is a new detection. Cloudflare Managed Ruleset N/A Vite - WASM Import Path Traversal - CVE:CVE-2025-31125 Log Block This is a new detection. - CVE-2025-68645: A Local File Inclusion (LFI) vulnerability in the Webmail Classic UI of Zimbra Collaboration Suite (ZCS) 10.0 and 10.1 allows unauthenticated remote attackers to craft requests to the
Cloudflare has deprecated the Workers Quick Editor dev tools inspector and replaced it with a lightweight log viewer.
This aligns our logging with
wrangler tailand gives us the opportunity to focus our efforts on bringing benefits from the work we have invested in observability, which would not be possible otherwise.We have made improvements to this logging viewer based on your feedback such that you can log object and array types, and easily clear the list of logs. This does not include class instances. Limitations are documented in the Workers Playground docs.
If you do need to develop your Worker with a remote inspector, you can still do this using Wrangler locally. Cloning a project from your quick editor to your computer for local development can be done with the
wrangler init --from-dashcommand. For more information, refer to Wrangler commands.
A new Workers Best Practices guide provides opinionated recommendations for building fast, reliable, observable, and secure Workers. The guide draws on production patterns, Cloudflare internal usage, and best practices observed from developers building on Workers.
Key guidance includes:
- Keep your compatibility date current and enable
nodejs_compat— Ensure you have access to the latest runtime features and Node.js built-in modules.
JSONC {"name": "my-worker","main": "src/index.ts",// Set this to today's date"compatibility_date": "2026-04-03","compatibility_flags": ["nodejs_compat"],}TOML name = "my-worker"main = "src/index.ts"# Set this to today's datecompatibility_date = "2026-04-03"compatibility_flags = [ "nodejs_compat" ]- Generate binding types with
wrangler types— Never hand-write yourEnvinterface. Let Wrangler generate it from your actual configuration to catch mismatches at compile time. - Stream request and response bodies — Avoid buffering large payloads in memory. Use
TransformStreamandpipeToto stay within the 128 MB memory limit and improve time-to-first-byte. - Use bindings, not REST APIs — Bindings to KV, R2, D1, Queues, and other Cloudflare services are direct, in-process references with no network hop and no authentication overhead.
- Use Queues and Workflows for background work — Move long-running or retriable tasks out of the critical request path. Use Queues for simple fan-out and buffering, and Workflows for multi-step durable processes.
- Enable Workers Logs and Traces — Configure observability before deploying to production so you have data when you need to debug.
- Avoid global mutable state — Workers reuse isolates across requests. Storing request-scoped data in module-level variables causes cross-request data leaks.
- Always
awaitorwaitUntilyour Promises — Floating promises cause silent bugs and dropped work. - Use Web Crypto for secure token generation — Never use
Math.random()for security-sensitive operations.
To learn more, refer to Workers Best Practices.
- Keep your compatibility date current and enable
Fine-grained permissions for Access policies and Access service tokens are available. These new resource-scoped roles expand the existing RBAC model, enabling administrators to grant permissions scoped to individual resources.
- Cloudflare Access policy admin: Can edit a specific Access policy in an account.
- Cloudflare Access service token admin: Can edit a specific Access service token in an account.
These roles complement the existing resource-scoped roles for Access applications, identity providers, and infrastructure targets.
For more information:
Disclaimer: Please note that v5.0.0-beta.1 is in Beta and we are still testing it for stability.
Full Changelog: v4.3.1...v5.0.0-beta.1 ↗
In this release, you'll see a large number of breaking changes. This is primarily due to a change in OpenAPI definitions, which our libraries are based off of, and codegen updates that we rely on to read those OpenAPI definitions and produce our SDK libraries. As the codegen is always evolving and improving, so are our code bases.
There may be changes that are not captured in this changelog. Feel free to open an issue to report any inaccuracies, and we will make sure it gets into the changelog before the v5.0.0 release.
Most of the breaking changes below are caused by improvements to the accuracy of the base OpenAPI schemas, which sometimes translates to breaking changes in downstream clients that depend on those schemas.
Please ensure you read through the list of changes below and the migration guide before moving to this version - this will help you understand any down or upstream issues it may cause to your environments.
The following resources have breaking changes. See the v5 Migration Guide ↗ for detailed migration instructions.
abusereportsacm.totaltlsapigateway.configurationscloudforceone.threateventsd1.databaseintel.indicatorfeedslogpush.edgeorigintlsclientauth.hostnamesqueues.consumersradar.bgprulesets.rulesschemavalidation.schemassnippetszerotrust.dlpzerotrust.networks
abusereports- Abuse report managementabusereports.mitigations- Abuse report mitigation actionsai.tomarkdown- AI-powered markdown conversionaigateway.dynamicrouting- AI Gateway dynamic routing configurationaigateway.providerconfigs- AI Gateway provider configurationsaisearch- AI-powered search functionalityaisearch.instances- AI Search instance managementaisearch.tokens- AI Search authentication tokensalerting.silences- Alert silence managementbrandprotection.logomatches- Brand protection logo match detectionbrandprotection.logos- Brand protection logo managementbrandprotection.matches- Brand protection match resultsbrandprotection.queries- Brand protection query managementcloudforceone.binarystorage- CloudForce One binary storageconnectivity.directory- Connectivity directory servicesd1.database- D1 database managementdiagnostics.endpointhealthchecks- Endpoint health check diagnosticsfraud- Fraud detection and preventioniam.sso- IAM Single Sign-On configurationloadbalancers.monitorgroups- Load balancer monitor groupsorganizations- Organization managementorganizations.organizationprofile- Organization profile settingsorigintlsclientauth.hostnamecertificates- Origin TLS client auth hostname certificatesorigintlsclientauth.hostnames- Origin TLS client auth hostnamesorigintlsclientauth.zonecertificates- Origin TLS client auth zone certificatespipelines- Data pipeline managementpipelines.sinks- Pipeline sink configurationspipelines.streams- Pipeline stream configurationsqueues.subscriptions- Queue subscription managementr2datacatalog- R2 Data Catalog integrationr2datacatalog.credentials- R2 Data Catalog credentialsr2datacatalog.maintenanceconfigs- R2 Data Catalog maintenance configurationsr2datacatalog.namespaces- R2 Data Catalog namespacesradar.bots- Radar bot analyticsradar.ct- Radar certificate transparency dataradar.geolocations- Radar geolocation datarealtimekit.activesession- Real-time Kit active session managementrealtimekit.analytics- Real-time Kit analyticsrealtimekit.apps- Real-time Kit application managementrealtimekit.livestreams- Real-time Kit live streamingrealtimekit.meetings- Real-time Kit meeting managementrealtimekit.presets- Real-time Kit preset configurationsrealtimekit.recordings- Real-time Kit recording managementrealtimekit.sessions- Real-time Kit session managementrealtimekit.webhooks- Real-time Kit webhook configurationstokenvalidation.configuration- Token validation configurationtokenvalidation.rules- Token validation rulesworkers.beta- Workers beta features
edit()update()
list()
create()get()update()
scan_list()scan_review()scan_trigger()
create()delete()list()
get()
list()
summary()timeseries()timeseries_groups()
changes()snapshot()
delete()
create()delete()edit()get()list()
- Type inference improvements: Allow Pyright to properly infer TypedDict types within SequenceNotStr
- Type completeness: Add missing types to method arguments and response models
- Pydantic compatibility: Ensure compatibility with Pydantic versions prior to 2.8.0 when using additional fields
- Multipart form data: Correctly handle sending multipart/form-data requests with JSON data
- Header handling: Do not send headers with default values set to omit
- GET request headers: Don't send Content-Type header on GET requests
- Response body model accuracy: Broad improvements to the correctness of models
- Discriminated unions: Correctly handle nested discriminated unions in response parsing
- Extra field types: Parse extra field types correctly
- Empty metadata: Ignore empty metadata fields during parsing
- Singularization rules: Update resource name singularization rules for better consistency
We're excited to announce GLM-4.7-Flash on Workers AI, a fast and efficient text generation model optimized for multilingual dialogue and instruction-following tasks, along with the brand-new @cloudflare/tanstack-ai ↗ package and workers-ai-provider v3.1.1 ↗.
You can now run AI agents entirely on Cloudflare. With GLM-4.7-Flash's multi-turn tool calling support, plus full compatibility with TanStack AI and the Vercel AI SDK, you have everything you need to build agentic applications that run completely at the edge.
@cf/zai-org/glm-4.7-flashis a multilingual model with a 131,072 token context window, making it ideal for long-form content generation, complex reasoning tasks, and multilingual applications.Key Features and Use Cases:
- Multi-turn Tool Calling for Agents: Build AI agents that can call functions and tools across multiple conversation turns
- Multilingual Support: Built to handle content generation in multiple languages effectively
- Large Context Window: 131,072 tokens for long-form writing, complex reasoning, and processing long documents
- Fast Inference: Optimized for low-latency responses in chatbots and virtual assistants
- Instruction Following: Excellent at following complex instructions for code generation and structured tasks
Use GLM-4.7-Flash through the Workers AI binding (
env.AI.run()), the REST API at/runor/v1/chat/completions, AI Gateway, or via workers-ai-provider for the Vercel AI SDK.Pricing is available on the model page or pricing page.
We've released
@cloudflare/tanstack-ai, a new package that brings Workers AI and AI Gateway support to TanStack AI ↗. This provides a framework-agnostic alternative for developers who prefer TanStack's approach to building AI applications.Workers AI adapters support four configuration modes — plain binding (
env.AI), plain REST, AI Gateway binding (env.AI.gateway(id)), and AI Gateway REST — across all capabilities:- Chat (
createWorkersAiChat) — Streaming chat completions with tool calling, structured output, and reasoning text streaming. - Image generation (
createWorkersAiImage) — Text-to-image models. - Transcription (
createWorkersAiTranscription) — Speech-to-text. - Text-to-speech (
createWorkersAiTts) — Audio generation. - Summarization (
createWorkersAiSummarize) — Text summarization.
AI Gateway adapters route requests from third-party providers — OpenAI, Anthropic, Gemini, Grok, and OpenRouter — through Cloudflare AI Gateway for caching, rate limiting, and unified billing.
To get started:
Terminal window npm install @cloudflare/tanstack-ai @tanstack/aiThe Workers AI provider for the Vercel AI SDK ↗ now supports three new capabilities beyond chat and image generation:
- Transcription (
provider.transcription(model)) — Speech-to-text with automatic handling of model-specific input formats across binding and REST paths. - Text-to-speech (
provider.speech(model)) — Audio generation with support for voice and speed options. - Reranking (
provider.reranking(model)) — Document reranking for RAG pipelines and search result ordering.
TypeScript import { createWorkersAI } from "workers-ai-provider";import {experimental_transcribe,experimental_generateSpeech,rerank,} from "ai";const workersai = createWorkersAI({ binding: env.AI });const transcript = await experimental_transcribe({model: workersai.transcription("@cf/openai/whisper-large-v3-turbo"),audio: audioData,mediaType: "audio/wav",});const speech = await experimental_generateSpeech({model: workersai.speech("@cf/deepgram/aura-1"),text: "Hello world",voice: "asteria",});const ranked = await rerank({model: workersai.reranking("@cf/baai/bge-reranker-base"),query: "What is machine learning?",documents: ["ML is a branch of AI.", "The weather is sunny."],});This release also includes a comprehensive reliability overhaul (v3.0.5):
- Fixed streaming — Responses now stream token-by-token instead of buffering all chunks, using a proper
TransformStreampipeline with backpressure. - Fixed tool calling — Resolved issues with tool call ID sanitization, conversation history preservation, and a heuristic that silently fell back to non-streaming mode when tools were defined.
- Premature stream termination detection — Streams that end unexpectedly now report
finishReason: "error"instead of silently reporting"stop". - AI Search support — Added
createAISearchas the canonical export (renamed from AutoRAG).createAutoRAGstill works with a deprecation warning.
To upgrade:
Terminal window npm install workers-ai-provider@latest ai
Workers VPC now supports Cloudflare Origin CA certificates when connecting to your private services over HTTPS. Previously, Workers VPC only trusted certificates issued by publicly trusted certificate authorities (for example, Let's Encrypt, DigiCert).
With this change, you can use free Cloudflare Origin CA certificates on your origin servers within private networks and connect to them from Workers VPC using the
httpsscheme. This is useful for encrypting traffic between the tunnel and your service without needing to provision certificates from a public CA.For more information, refer to Supported TLS certificates.
Cloudflare WAN now displays your Anycast IP addresses directly in the dashboard when you configure IPsec or GRE tunnels.
Previously, customers received their Anycast IPs during onboarding or had to retrieve them with an API call. The dashboard now pre-loads these addresses, reducing setup friction and preventing configuration errors.
No action is required. All Cloudflare WAN customers can see their Anycast IPs in the tunnel configuration form automatically.
For more information, refer to Configure tunnel endpoints.
Cloudflare's network now supports real-time content conversion at the source, for enabled zones using content negotiation ↗ headers. When AI systems request pages from any website that uses Cloudflare and has Markdown for Agents enabled, they can express the preference for
text/markdownin the request: our network will automatically and efficiently convert the HTML to markdown, when possible, on the fly.Here is a curl example with the
Acceptnegotiation header requesting this page from our developer documentation:Terminal window curl https://developers.cloudflare.com/fundamentals/reference/markdown-for-agents/ \-H "Accept: text/markdown"The response to this request is now formatted in markdown:
HTTP/2 200date: Wed, 11 Feb 2026 11:44:48 GMTcontent-type: text/markdown; charset=utf-8content-length: 2899vary: acceptx-markdown-tokens: 725content-signal: ai-train=yes, search=yes, ai-input=yes---title: Markdown for Agents · Cloudflare Agents docs---## What is Markdown for AgentsMarkdown has quickly become the lingua franca for agents and AI systemsas a whole. The format’s explicit structure makes it ideal for AI processing,ultimately resulting in better results while minimizing token waste....Refer to our developer documentation and our blog announcement ↗ for more details.
Radar now includes content type insights for AI bot and crawler traffic. The new
content_typedimension and filter shows the distribution of content types returned to AI crawlers, grouped by MIME type category.The content type dimension and filter are available via the following API endpoints:
Content type categories:
- HTML - Web pages (
text/html) - Images - All image formats (
image/*) - JSON - JSON data and API responses (
application/json,*+json) - JavaScript - Scripts (
application/javascript,text/javascript) - CSS - Stylesheets (
text/css) - Plain Text - Unformatted text (
text/plain) - Fonts - Web fonts (
font/*,application/font-*) - XML - XML documents and feeds (
text/xml,application/xml,application/rss+xml,application/atom+xml) - YAML - Configuration files (
text/yaml,application/yaml) - Video - Video content and streaming (
video/*,application/ogg,*mpegurl) - Audio - Audio content (
audio/*) - Markdown - Markdown documents (
text/markdown) - Documents - PDFs, Office documents, ePub, CSV (
application/pdf,application/msword,text/csv) - Binary - Executables, archives, WebAssembly (
application/octet-stream,application/zip,application/wasm) - Serialization - Binary API formats (
application/protobuf,application/grpc,application/msgpack) - Other - All other content types
Additionally, individual bot information pages ↗ now display content type distribution for AI crawlers that exist in both the Verified Bots and AI Bots datasets.
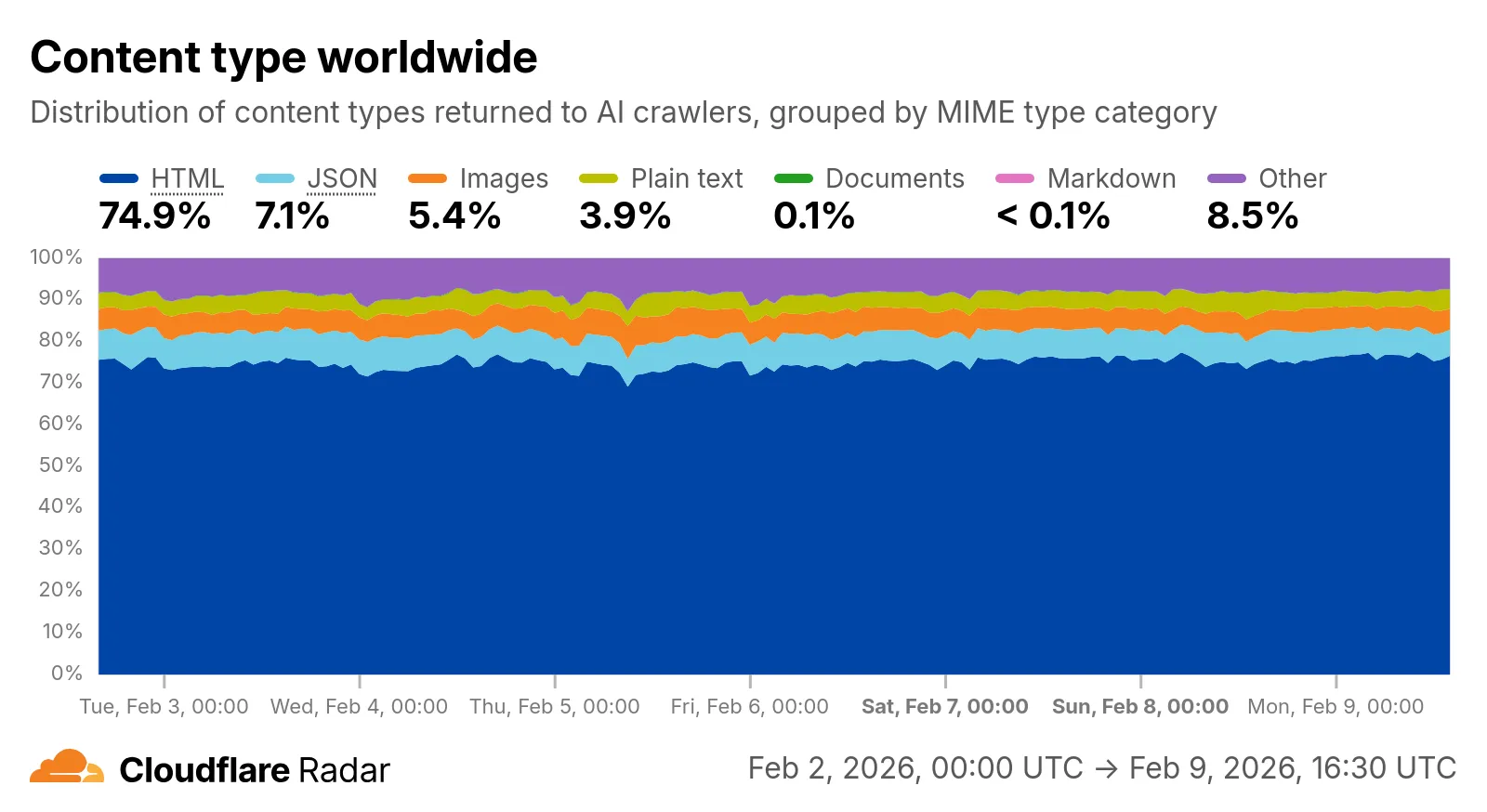
Check out the AI Insights page ↗ to explore the data.
- HTML - Web pages (
We have significantly upgraded our Logo Matching capabilities within Brand Protection. While previously limited to approximately 100% matches, users can now detect a wider range of brand assets through a redesigned matching model and UI.
- Configurable match thresholds: Users can set a minimum match score (starting at 75%) when creating a logo query to capture subtle variations or high-quality impersonations.
- Visual match scores: Allow users to see the exact percentage of the match directly in the results table, highlighted with color-coded lozenges to indicate severity.
- Direct logo previews: Available in the Cloudflare dashboard — similar to string matches — to verify infringements at a glance.
- Expose sophisticated impersonators who use slightly altered logos to bypass basic detection filters.
- Faster triage of the most relevant threats immediately using visual indicators, reducing the time spent manually reviewing matches.
Ready to protect your visual identity? Learn more in our Brand Protection documentation.
In January 2025, we announced the launch of the new Terraform v5 Provider. We greatly appreciate the proactive engagement and valuable feedback from the Cloudflare community following the v5 release. In response, we have established a consistent and rapid 2-3 week cadence ↗ for releasing targeted improvements, demonstrating our commitment to stability and reliability.
With the help of the community, we have a growing number of resources that we have marked as stable ↗, with that list continuing to grow with every release. The most used resources ↗ are on track to be stable by the end of March 2026, when we will also be releasing a new migration tool to help you migrate from v4 to v5 with ease.
This release brings new capabilities for AI Search, enhanced Workers Script placement controls, and numerous bug fixes based on community feedback. We also begun laying foundational work for improving the v4 to v5 migration process. Stay tuned for more details as we approach the March 2026 release timeline.
Thank you for continuing to raise issues. They make our provider stronger and help us build products that reflect your needs.
- ai_search_instance: add data source for querying AI Search instances
- ai_search_token: add data source for querying AI Search tokens
- account: add support for tenant unit management with new
unitfield - account: add automatic mapping from
managed_by.parent_org_idtounit.id - authenticated_origin_pulls_certificate: add data source for querying authenticated origin pull certificates
- authenticated_origin_pulls_hostname_certificate: add data source for querying hostname-specific authenticated origin pull certificates
- authenticated_origin_pulls_settings: add data source for querying authenticated origin pull settings
- workers_kv: add
valuefield to data source to retrieve KV values directly - workers_script: add
scriptfield to data source to retrieve script content - workers_script: add support for
simplerate limit binding - workers_script: add support for targeted placement mode with
placement.targetarray for specifying placement targets (region, hostname, host) - workers_script: add
placement_modeandplacement_statuscomputed fields - zero_trust_dex_test: add data source with filter support for finding specific tests
- zero_trust_dlp_predefined_profile: add
enabled_entriesfield for flexible entry management
- account: map
managed_by.parent_org_idtounit.idin unmarshall and add acceptance tests - authenticated_origin_pulls_certificate: add certificate normalization to prevent drift
- authenticated_origin_pulls: handle array response and implement full lifecycle
- authenticated_origin_pulls_hostname_certificate: fix resource and tests
- cloudforce_one_request_message: use correct
request_idfield instead ofidin API calls - dns_zone_transfers_incoming: use correct
zone_idfield instead ofidin API calls - dns_zone_transfers_outgoing: use correct
zone_idfield instead ofidin API calls - email_routing_settings: use correct
zone_idfield instead ofidin API calls - hyperdrive_config: add proper handling for write-only fields to prevent state drift
- hyperdrive_config: add normalization for empty
mtlsobjects to prevent unnecessary diffs - magic_network_monitoring_rule: use correct
account_idfield instead ofidin API calls - mtls_certificates: fix resource and test
- pages_project: revert build_config to computed optional
- stream_key: use correct
account_idfield instead ofidin API calls - total_tls: use upsert pattern for singleton zone setting
- waiting_room_rules: use correct
waiting_room_idfield instead ofidin API calls - workers_script: add support for placement mode/status
- zero_trust_access_application: update v4 version on migration tests
- zero_trust_device_posture_rule: update tests to match API
- zero_trust_dlp_integration_entry: use correct
entry_idfield instead ofidin API calls - zero_trust_dlp_predefined_entry: use correct
entry_idfield instead ofidin API calls - zero_trust_organization: fix plan issues
- add state upgraders to 95+ resources to lay the foundation for replacing Grit (still under active development)
- certificate_pack: add state migration handler for SDKv2 to Framework conversion
- custom_hostname_fallback_origin: add comprehensive lifecycle test and migration support
- dns_record: add state migration handler for SDKv2 to Framework conversion
- leaked_credential_check: add import functionality and tests
- load_balancer_pool: add state migration handler with detection for v4 vs v5 format
- pages_project: add state migration handlers
- tiered_cache: add state migration handlers
- zero_trust_dlp_predefined_profile: deprecate
entriesfield in favor ofenabled_entries